Tabla de contenidos
- Introducción
- Plugin Dowload raster GEE
- ¿Cómo funciona el complemento?
- Probando el complemento
- Resultados obtenidos
- Reflexión final
Introducción
En estos tiempos, donde la cantidad de información disponible se ha multiplicado exponencialmente, se hace necesario contar con herramientas eficientes para obtener y procesar grandes volúmenes de datos. En este sentido, Google Earth Engine (GEE) se posiciona como una excelente solución para obtener datos espaciales en tiempos relativamente cortos y al aprovechar los beneficios de la tecnología en la nube (Cloud Computing), estamos optimizando recursos, por el simple hecho de contar con la potencia y escalabilidad de los servidores remotos que nos facilitan el acceso, manejo y análisis de los datos geoespaciales disponibles.
Para empezar a usar la plataforma del GEE, existen varias opciones que nos permiten interactuar con lenguajes de programación, dentro del editor de código del mismo GEE empleamos el lenguaje JavaScript, de la misma manera, podemos aprovechar sus ventajas a través del lenguaje Python gracias a la API del GEE (earthengine-api) y de una manera más interactiva a través del paquete de Python geemap. Si bien hablamos de algunas de las opciones, para quienes requieren de los datos de una manera rápida y tienen poco conocimiento de programación, en esta oportunidad hablare de la posibilidad de acceder a las capas de tipo ráster disponibles en GEE pero desde el entorno de QGIS, todo ello gracias al complemento «Download raster GEE«.
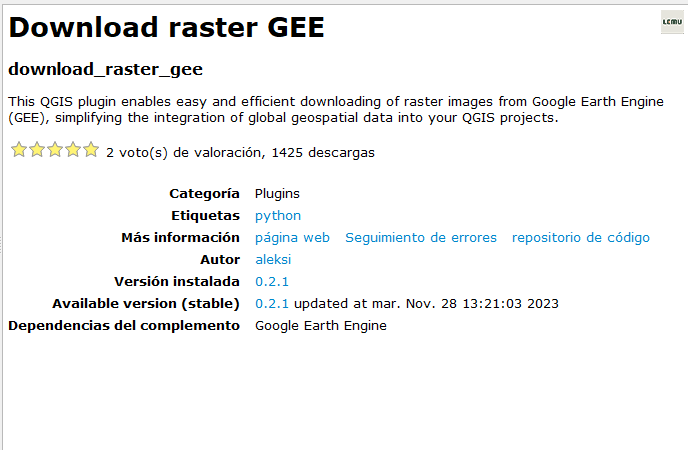
Plugin Dowload raster GEE
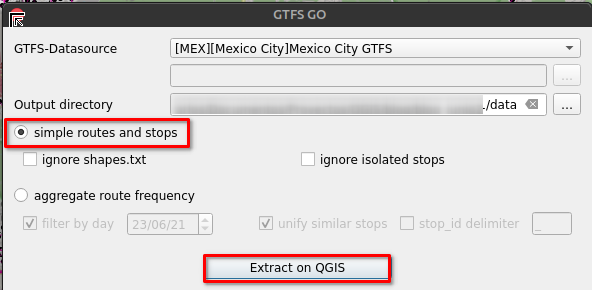
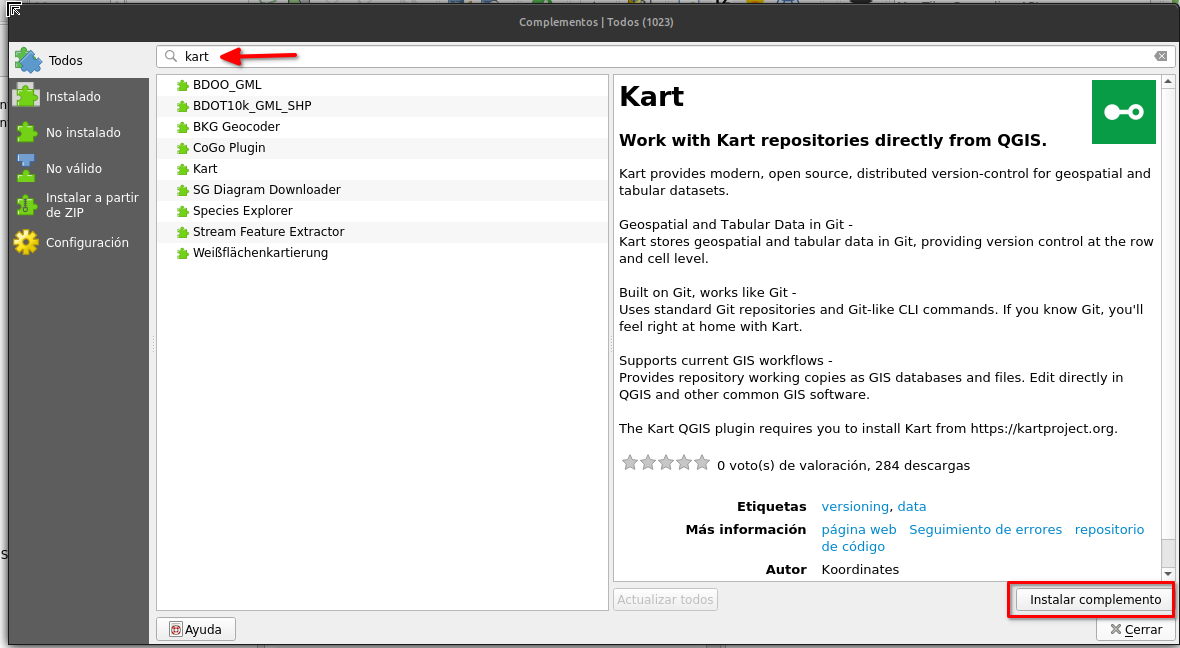
De acuerdo a lo mencionado en su repositorio, el complemento nos permite descargar capas ráster de GEE, apoyándonos con archivos de tipo vectorial (Shapefiles) para determinar una región de interés para luego de ser seleccionada, podamos acceder fácilmente a los datos de imágenes rasterizadas. El complemento puede ser instalada directamente desde el administrador de complementos en QGIS.
Para utilizar adecuadamente el complemento se debe seguir los siguientes pasos:
- Cargar un archivo en formato Shapefile que define la región de interés.
- Activar el complemento y seleccione el archivo Shapefile como región de interés.
- Seleccione la fuente datos requerido y seleccionar los parámetros necesarios como la fecha y el tipo de imagen.
- Hacer Click en ‘Download‘ para obtener los datos ráster de GEE.
Dependencias del complemento
Para lograr ejecutar el complemento sin problemas debemos cumplir algunos requisitos, entre ellos:
- Tener una cuenta valida en GEE: https://earthengine.google.com/
- Tener pre-instalado el plugin de GEE en QGIS: https://plugins.qgis.org/plugins/ee_plugin/. En caso de no tenerlo se instalará de manera automática al instalar el complemento «download_raster«.
¿Cómo funciona el complemento?
Una vez que el complemento está instalado en QGIS, uno podrá realizar diversas solicitudes para recuperar información del catálogo de datos disponible en GEE y mostrarla, así como para generar información válida para descargar según los requerimientos de zona de interés, fechas y tipo de imagen.
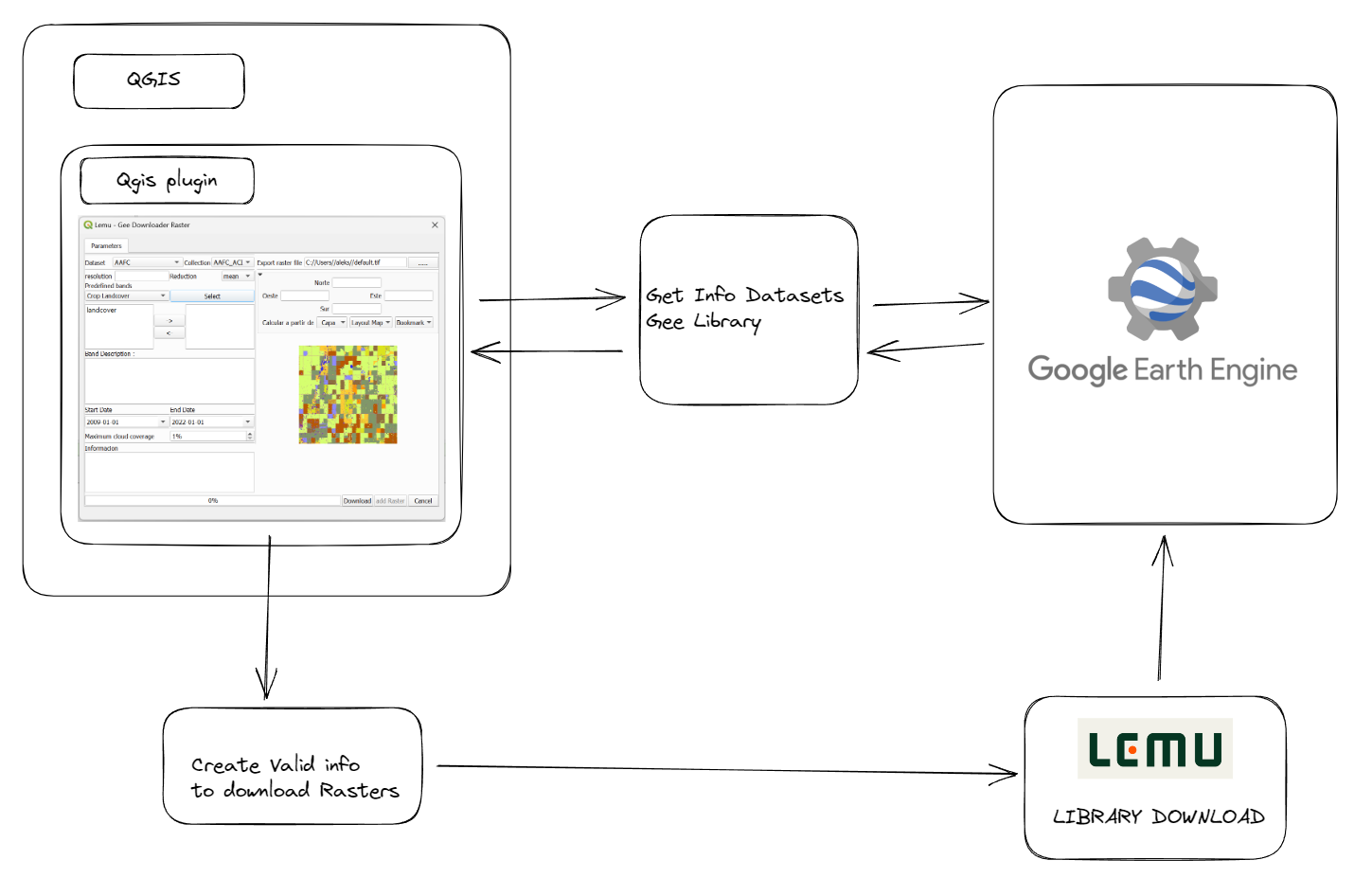
Probando el complemento
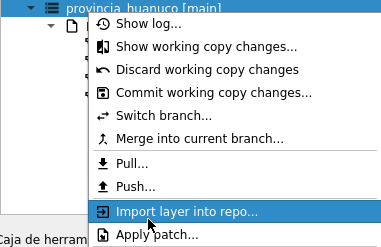
Para probar el complemento vamos a descargar una imagen que tiene como área de interés al Perú, seleccionamos desde los datos provenientes de MODIS, los que corresponden a la Producción Primaria Neta (Npp), el detalle lo podemos revisar del catálogo de GEE (MOD17A3HGF.061: Terra Net Primary Production Gap-Filled Yearly Global 500m). Como se aprecia en la figura de abajo, primero ubicamos la imagen ráster de MODIS e indicamos la resolución (tamaño del píxel), luego seleccionamos la banda correspondiente, en nuestro caso será Npp. Se mantuvo el rango de fechas por defecto, luego seleccionamos la capa vectorial como nuestra área de interés y también definimos la ruta y el nombre de la capa a descargar en formato tif. Finalmente solo debemos hacer click en el botón Download y esperar que se complete la descarga.
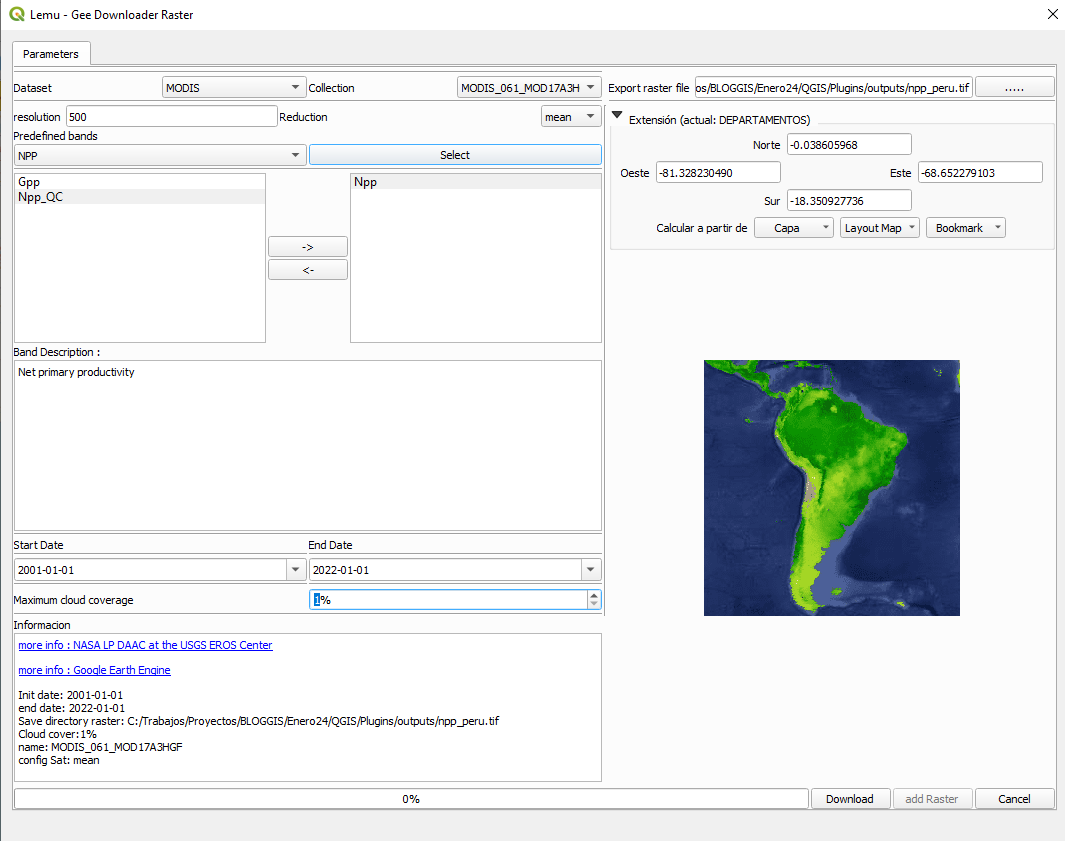
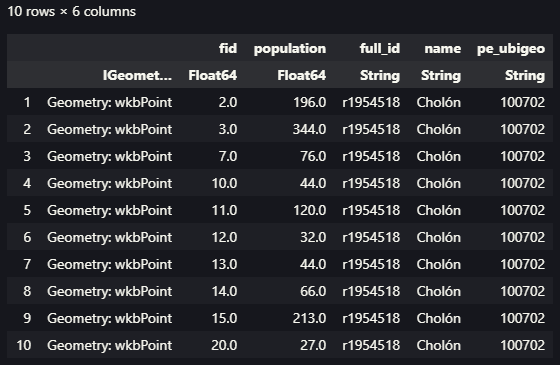
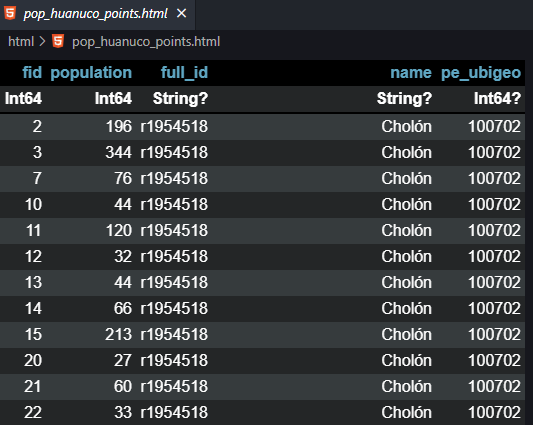
Empleando el mismo procedimiento decidimos descargar desde otra fuente de datos, en este caso de la NASA, lo que corresponde al porcentaje del área de píxeles cubierta por árboles (tree_canopy_cover). El detalle lo podemos revisar en Global Forest Cover Change (GFCC) Tree Cover Multi-Year Global 30m. Como se aprecia solicitaremos la descarga de una capa con mayor resolución, por lo tanto, se modificó el área de interés al Departamento de Huánuco en Perú.
Resultados obtenidos
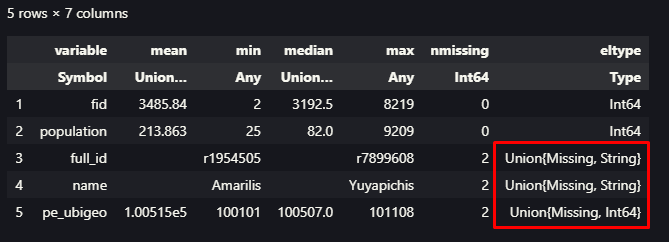
Dependiendo de la extensión de tu área de interés y la resolución establecida, la descarga puede tomar su tiempo, por otro lado, en algunos casos debemos hacer un paso previo para tener nuestra capa en las unidades correctas. Para la Npp, debemos ajustarlo de acuerdo al valor de escala que ha sido establecido en la tabla de la siguiente figura.
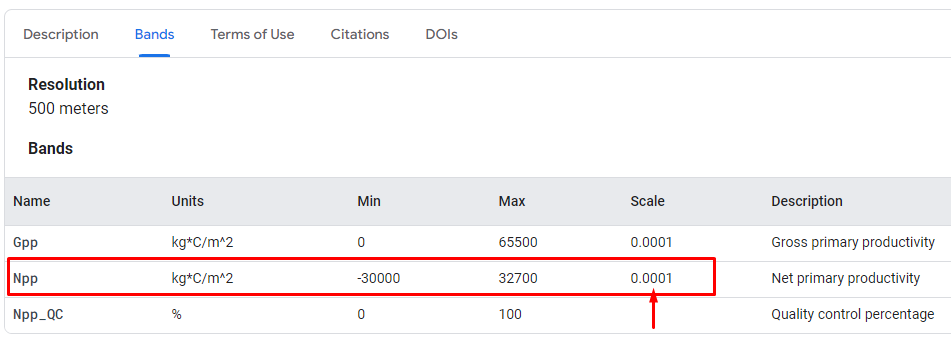
Por lo mencionado dentro de QGIS usando la calculadora ráster solo debemos multiplicar la capa por 0.0001, luego tendremos nuestra capa con las unidades correspondientes a kg*C/m2 .
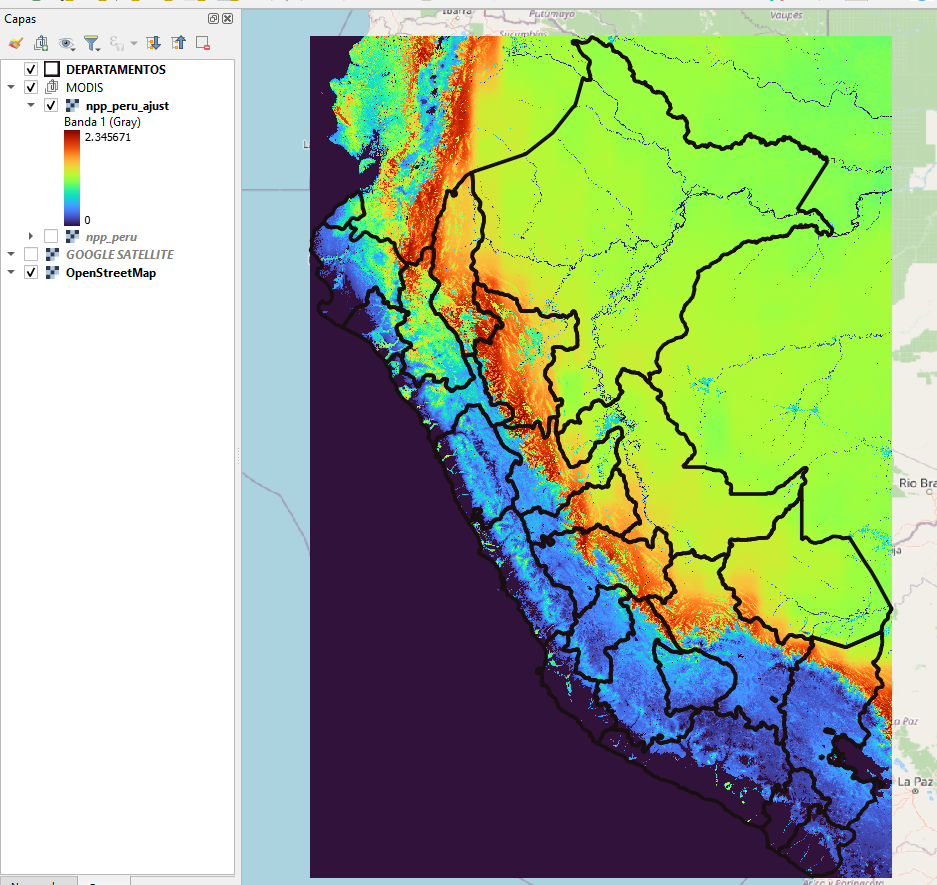
Para el segundo resultado las unidades están en porcentajes.

Reflexión final
Si bien trabajar dentro del editor de código del GEE te permite una mayor flexibilidad y mayores opciones para aprovechar las ventajas de trabajar desde la nube, todo ello se traduce en obtener mejores resultados, a veces solo necesitamos descargar una capa ráster y para quienes no se encuentran muy familiarizados con los lenguajes de programación, el uso de este complemento quizás le pueda resultar útil. Debo reconocer que mientras lo estaba probando con distintas fuentes de datos, no funcionó de manera muy óptima en algunos casos, tomando quizás más tiempo si lo comparamos cuando uno lo trabaja desde el editor de código. En fin, espero que lo puedan probar y puedan sacar sus propias conclusiones.
Se elaboró el siguiente video para mostrar el procedimiento seguido.

![\[f(x) = p * e^\frac {-x^2}{\beta}\]](https://www.educagis.com/wpcarlos/wp-content/ql-cache/quicklatex.com-e260906edc171653377227f3f62ea381_l3.png "Rendered by QuickLaTeX.com")