Tabla de contenidos
- Introducción
- Detalles sobre DataVoyager.jl
- Uso de DataVoyager
- Opciones dentro de DataVoyager
- Uso de nuestro datos
- Reflexión Final
Introducción
En busca de herramientas que nos permiten visualizar nuestros datos y a modo de complementar lo que vimos con VegaLite en una entrada anterior, en esta oportunidad probaremos el uso de un paquete de Julia denominado DataVoyager.jl. Nuestro objetivo será mostrar de manera práctica las ventajas de trabajar con una herramienta interactiva de visualización que nos puede ayudar como parte del proceso de exploración inicial de nuestros datos.
Detalles sobre DataVoyager.jl
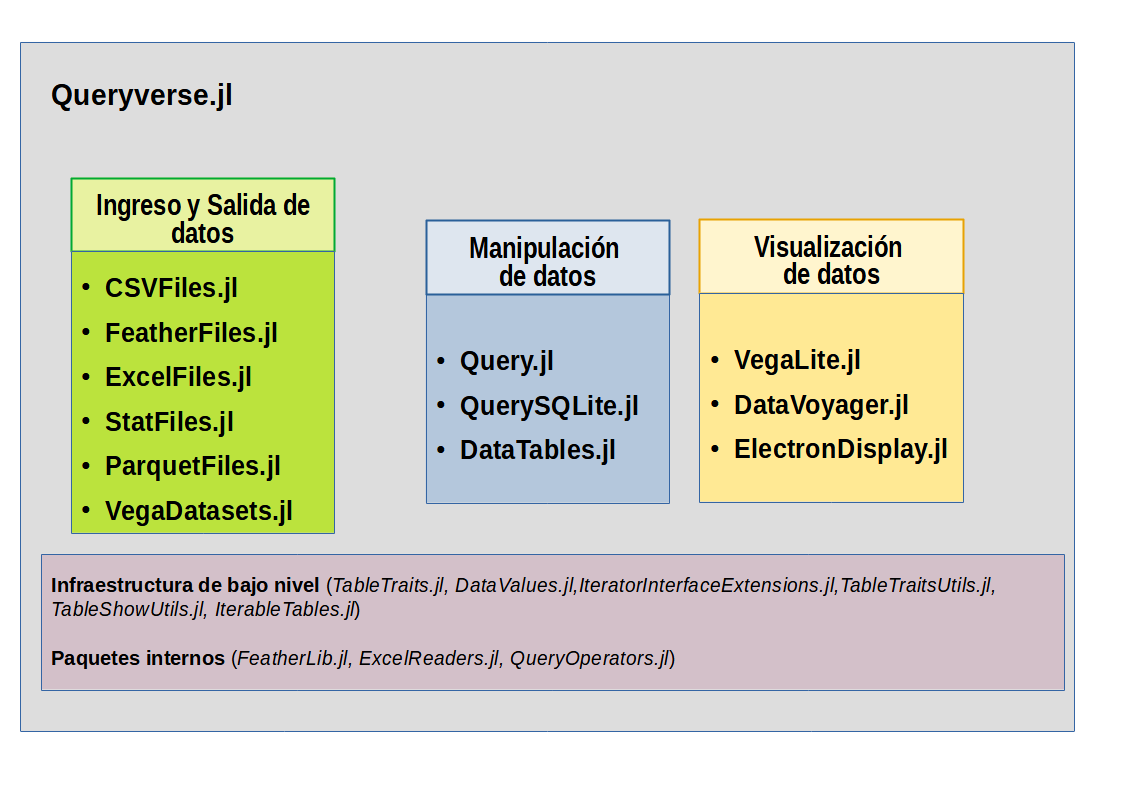
En principio, debemos entender que este paquete de Julia viene integrado dentro del metapaquete Queryverse, logrando proporcionar herramientas interactivas de exploración de datos. Se basa en el proyecto Voyager y está estrechamente integrado con VegaLite.jl. Como vemos, el paquete usa como fuente Vega, que trabaja a través de una gramática de visualización, un lenguaje declarativo para crear, guardar y compartir diseños de visualización interactivos, el mismo que a través de su aplicativo Voyager presenta una interfaz de visualización para la exploración de datos. Proporciona una interfaz para especificar la especificación Vega-Lite, con recomendaciones de gráficos impulsadas por el motor de recomendación de visualización Compass (como lenguaje de consulta). Como dato adicional, Voyager además de ser utilizado por Julia a través de DataVoyager, para quienes tienen la costumbre de usar JupyterLab, existe una extensión para que lo puedan probar.
Uso de DataVoyager
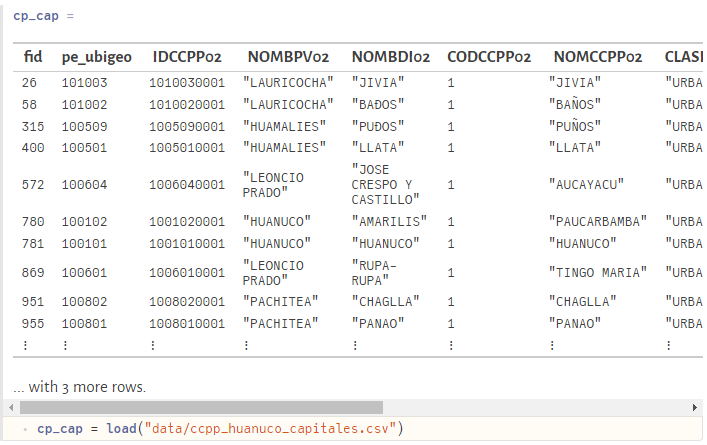
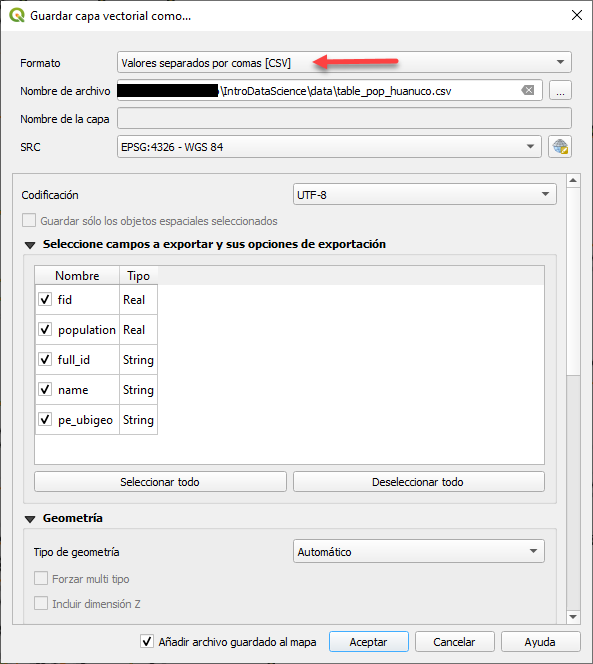
Para nuestra demostración vamos a emplear unos datos en formato CSV y de libre acceso: Crop Yield and Production. Como primera acción debemos instalar los paquetes requeridos. Podemos desde una IDE como Visual Studio Code, activar el REPL con las teclas Alt j + Alt o, y luego de usar ], adicionamos los paquetes VegaDatasets, DataVoyager, CSVFiles, DataFrames y VegaLite.
(@v1.7) pkg>add <package>Vamos a generar un archivo que en mi caso lo denominé eda.jl, para iniciar nuestro código activando los paquetes instalados.
using VegaDatasets
using DataVoyager
using CSVFiles
using DataFrames
using VegaLite Ahora como primer ejemplo emplearemos una de los datos disponibles que tenemos al usar VegaDatasets, nos referimos a «iris«.
dat_iris = dataset("iris") |> Voyager()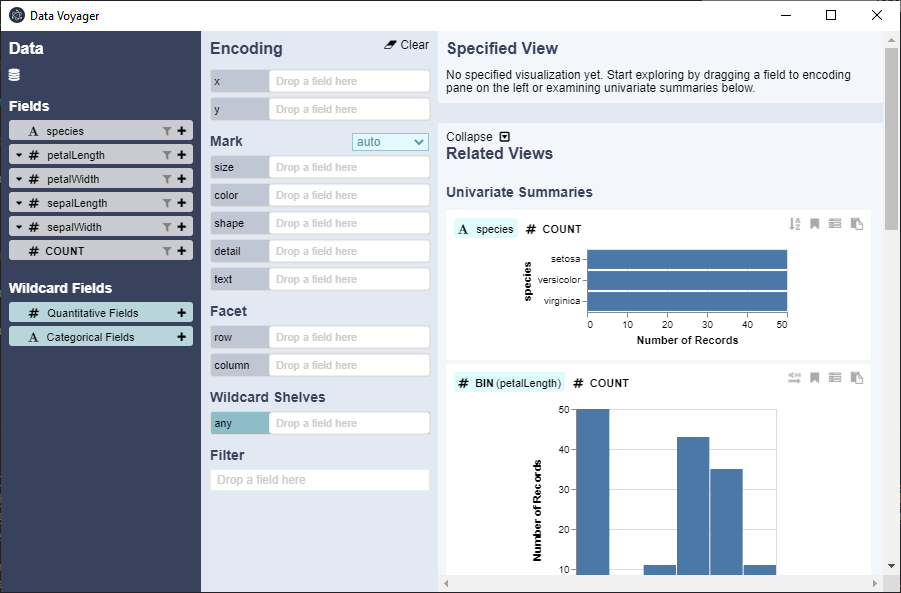
Opciones dentro de DataVoyager
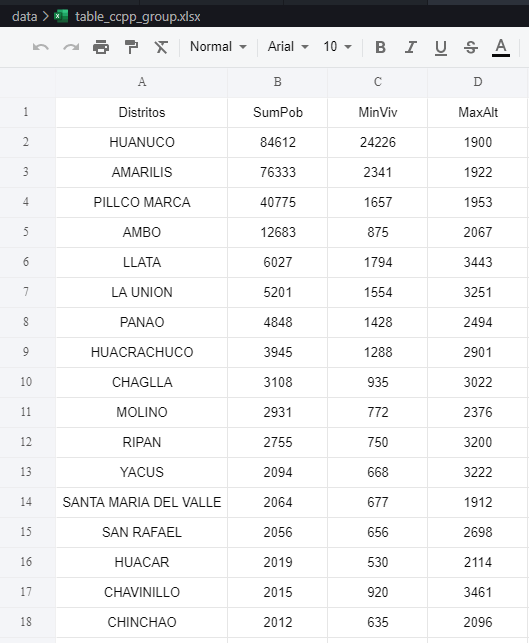
Como se aprecia en la imagen previa, en digamos el campo de datos, ha reconocido las columnas de los datos, colocando el símbolo «#» al inicio para aquellos que presentan datos de tipo numérico o cuantitativo y «A«, para aquellos de tipo nominal. A partir de ahora queda a nuestro criterio ir agrupando los datos en los ejes X e Y respectivos (solo se arrastran), teniendo como una de las opciones cuando se visualizan nuestros datos el poder diferenciarlos por colores arrastrando dentro de «Mark» en donde indica «color» por ejemplo la columna de datos «species» y también lo podemos dividirlos en files o columnas si arrastramos los mismos datos dentro de donde indica «Facet«.
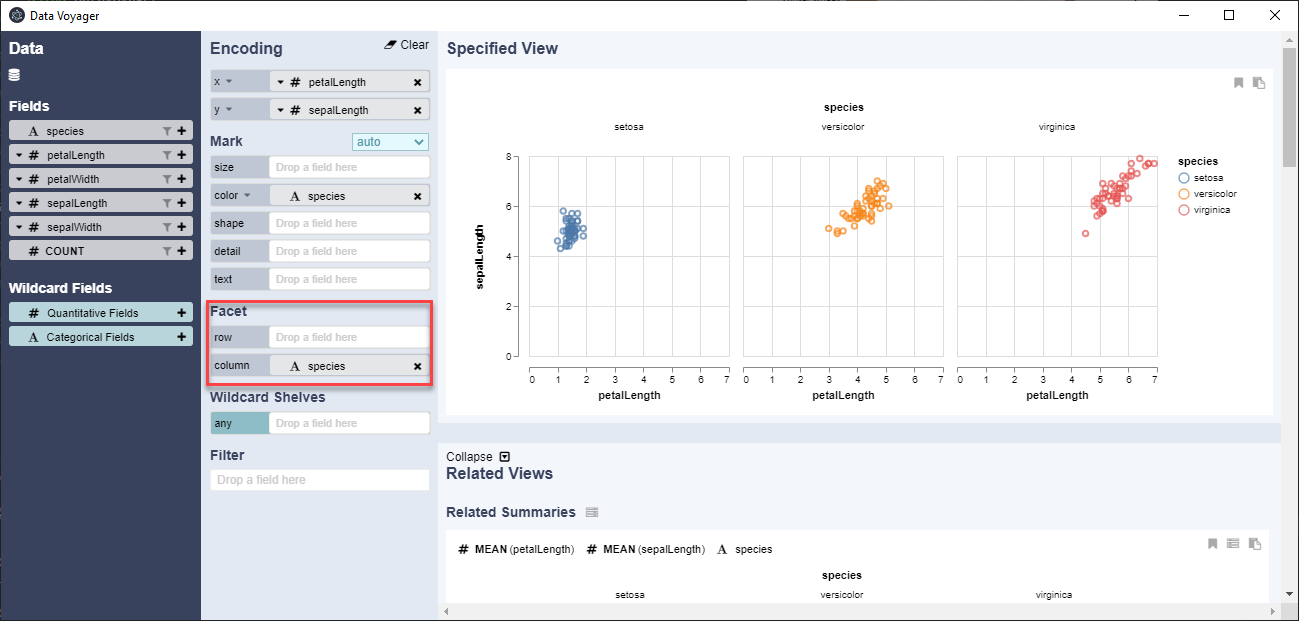
Otra opción que podemos apreciar es la posibilidad de incorporar algunos filtros, como ejemplo arrastramos una columna de datos numéricos con la finalidad de reducir los valores a un rango específico de valores, con la finalidad de ajustar nuestro gráfico. Como se aprecia en la figura siguiente, se elimina valores de una especie que esta fuera del rango establecido por el filtro.
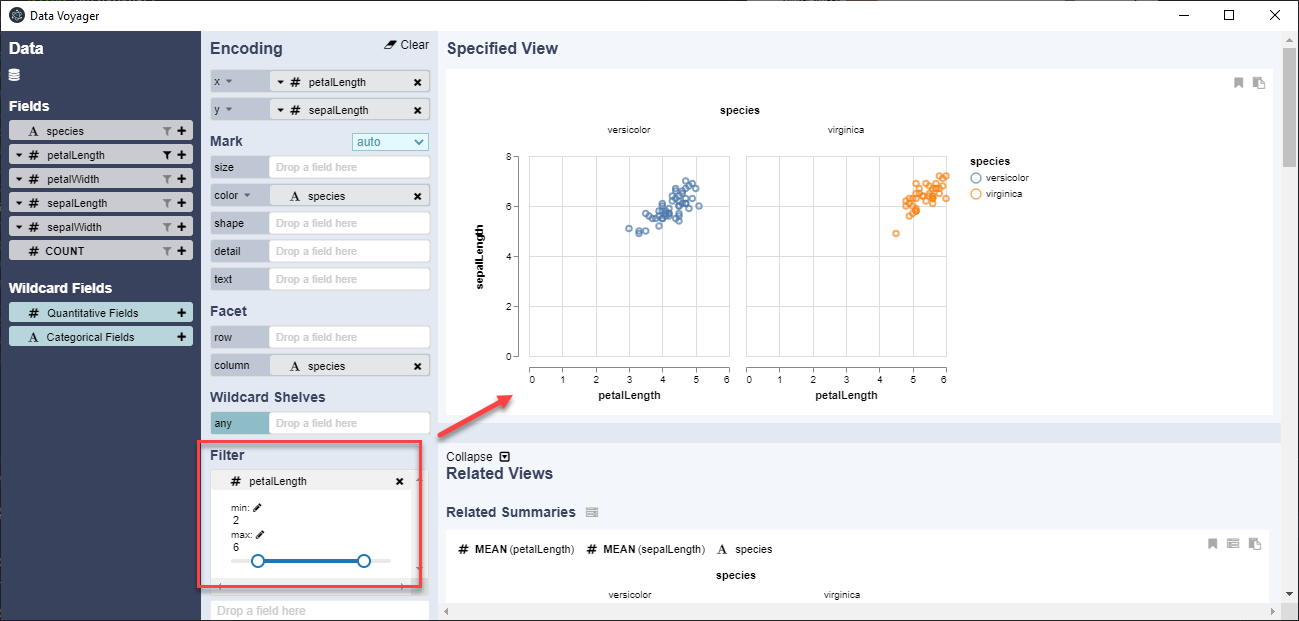
Uso de nuestro datos
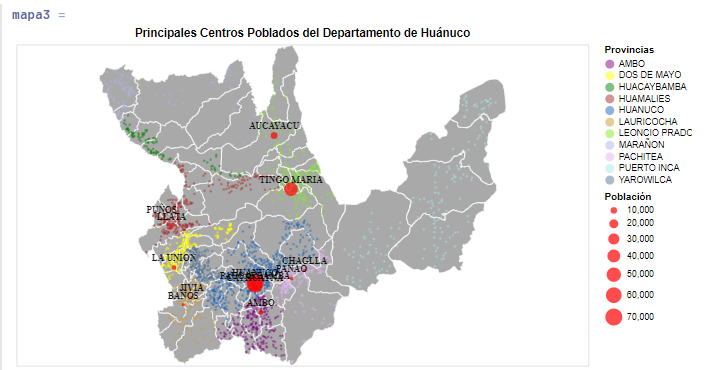
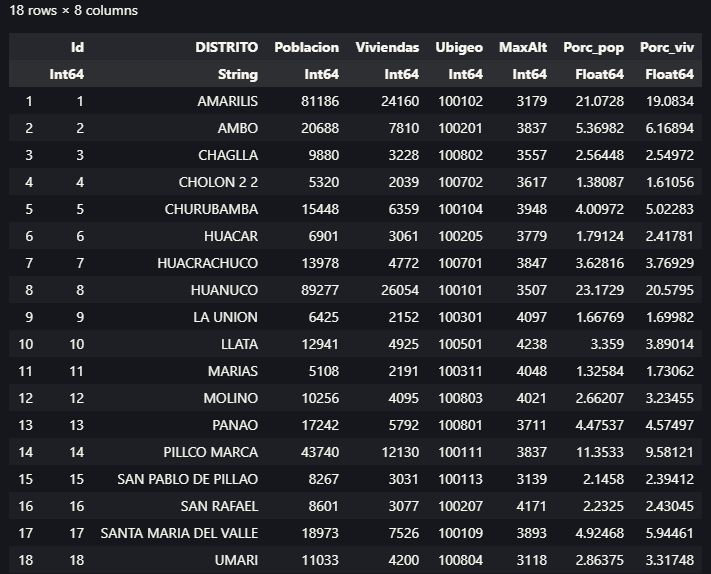
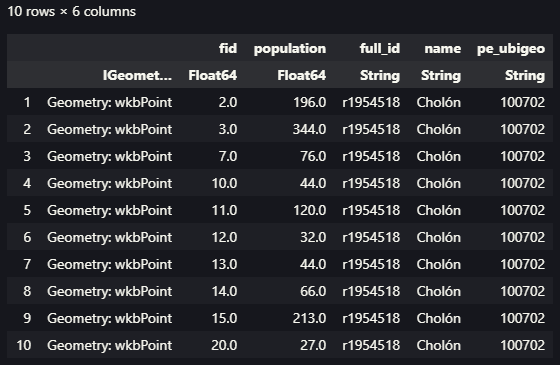
Ahora nos toca usar los datos que fueron descargados de la fuente ya mencionada. Seguiremos el mismo procedimiento seguido con la diferencia que debemos agregar el paso previo de leer datos en formato CSV, empleando el paquete CSVFiles.jl, luego con el paquete DataFrames.jl generar nuestra estructura de datos bajo el esquema de los Dataframes.
crop_data = load("voyager/data/crop_production.csv") |>DataFrame
v = crop_data |> Voyager()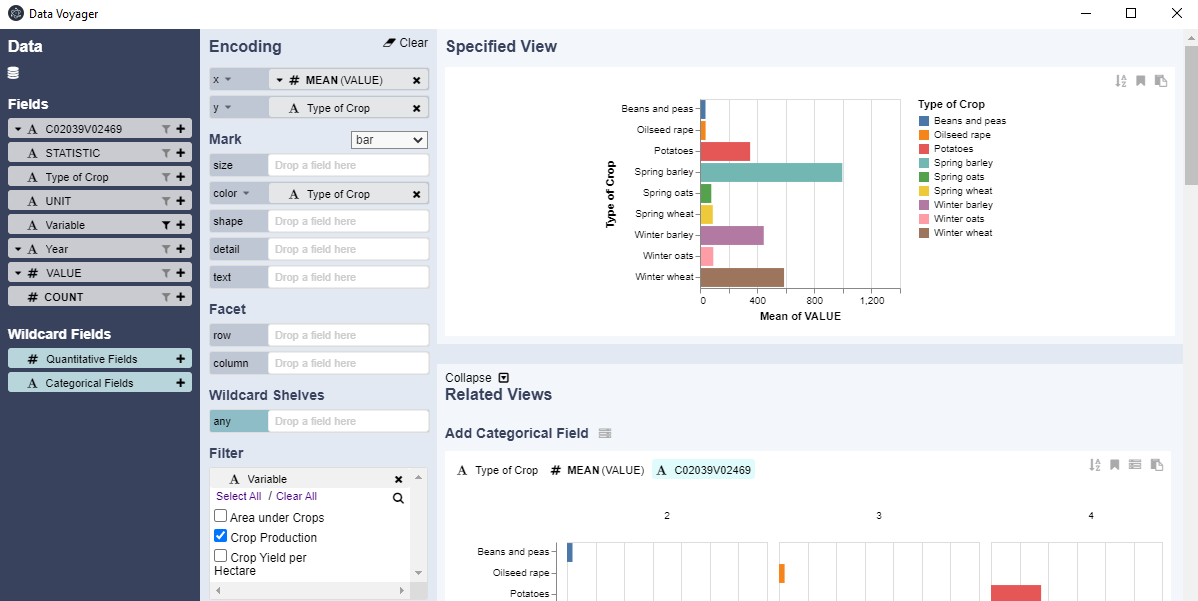
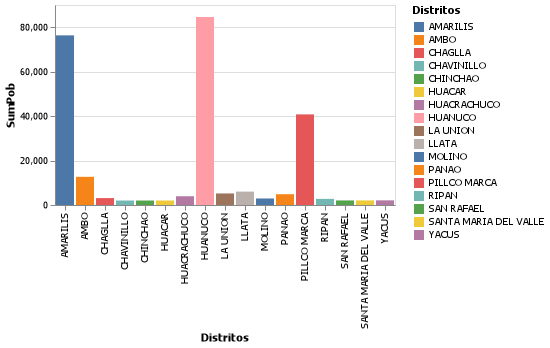
Luego de ajustar nuestras columnas de datos empleando las opciones que tenemos dentro de esta herramienta, vamos a generar un gráfico que será mostrado en nuestra vista específica. Finalmente si estamos conforme con el resultado, es obvio que necesitamos exportarlo a un formato de imagen por lo general para que puede ser incluido en quizás alguna presentación que necesitamos realizar. Para ello podemos seguir las indicaciones del siguiente código en Julia.
plot1 = v[]
plot1 |> save("voyager/output/prod_media.svg")Si bien podemos exportarlo a otros formatos como *.png, se recomienda emplear el formato *.svg, con la finalidad de tener una mejor presentación sin alteración en la calidad de la imagen.
Reflexión Final
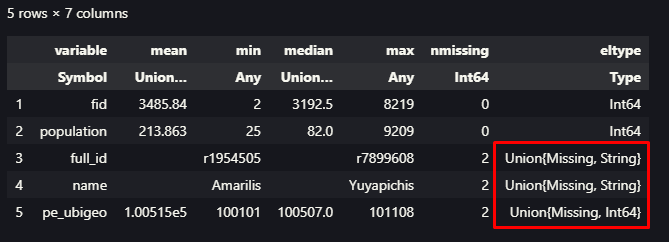
Siempre considero importante tener la posibilidad de explorar nuestros datos de manera rápida, ahora conocemos una herramienta que nos permite realizarlo de manera interactiva y de manera muy «visual», generando gráficos de manera rápida y de manera intuitiva, aunque es verdad que estamos limitados en el conocimiento más profundo de los datos, sobre todo desde el lado de la calidad de los mismos, es decir, a primera vista no podríamos darnos cuenta si existen datos faltantes por ejemplo. En general considero que esta herramienta podría ser muy útil para datos que de antemano conocemos que son confiables y necesitamos mostrar gráficos para una presentación rápida. Mientras exploraba la herramienta, me pude dar cuenta que la aplicación propia del mismo Voyager, presenta mayores opciones, les recomiendo probarla y si quieren profundizar también pueden revisar su documentación que es muy completa sobre todo lo que podríamos realizar con esta herramienta. También logre encontrar un paper sobre el mismo.
Bueno, espero que la herramienta presentada sea de mucha utilidad al momento de hacer una exploración inicial de sus datos. De la misma manera se ha elaborado un video sobre el uso de esta herramienta para que puedan ver con mayor detalle las opciones que fueron empleadas.