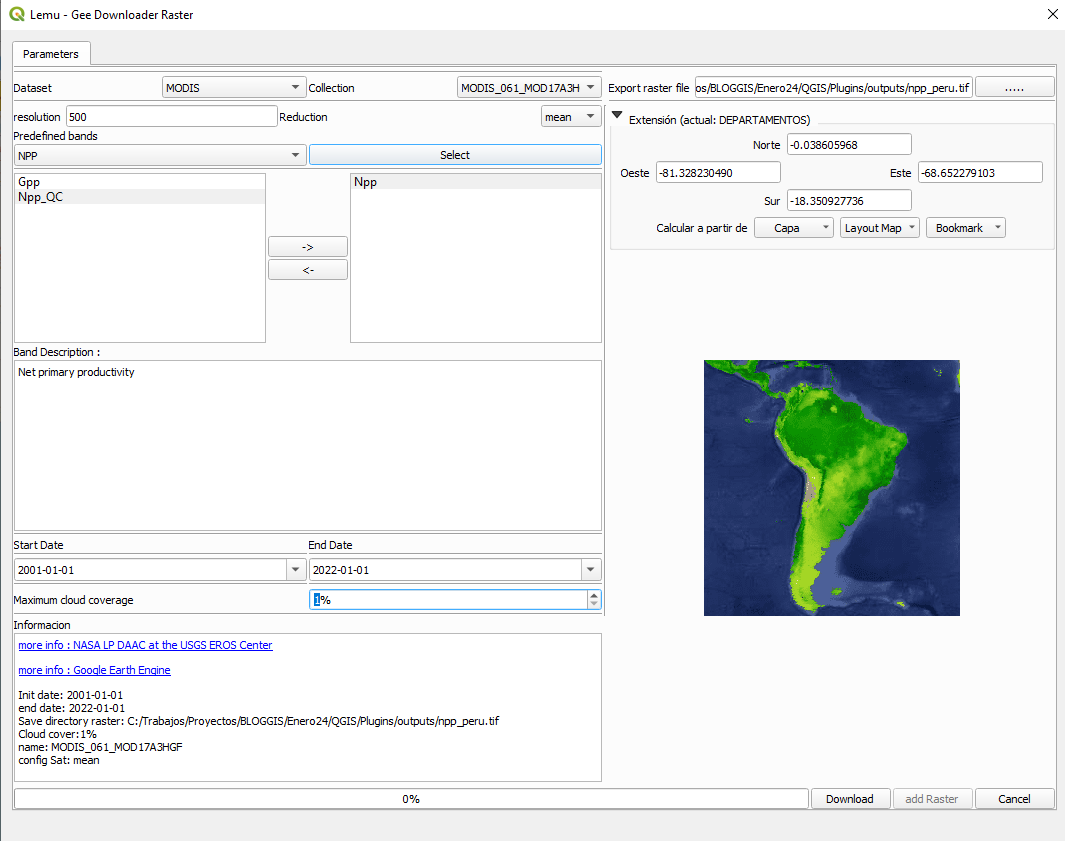
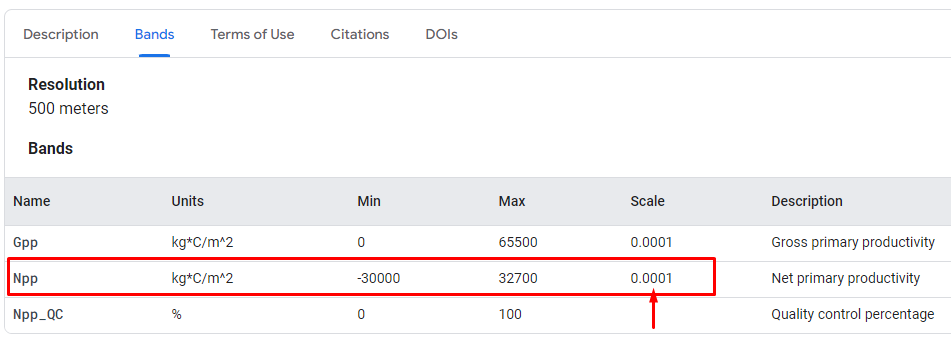
Tabla de contenidos
Introducción
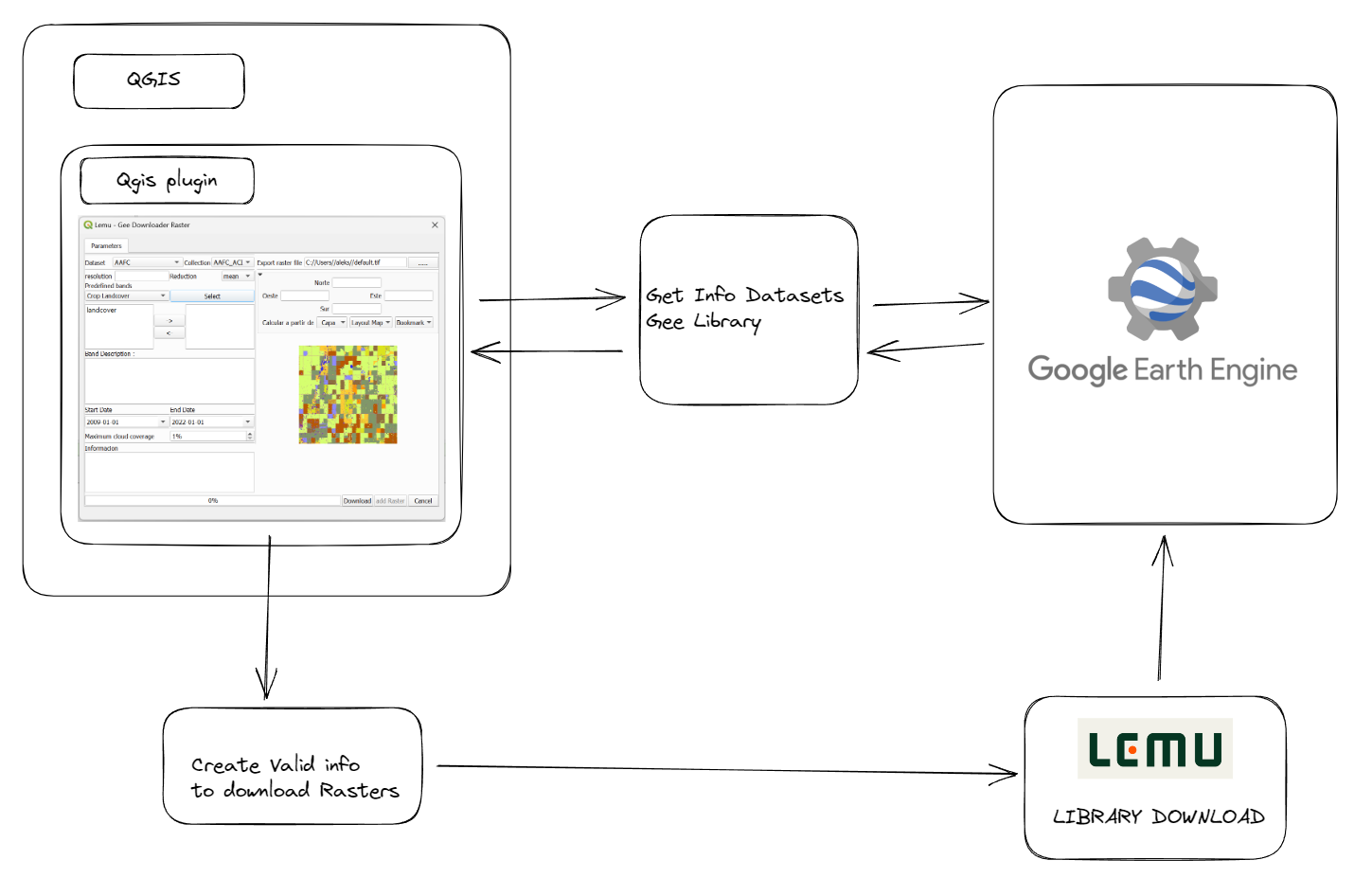
Cuando desarrollamos nuestro proyectos siempre buscamos la manera de trabajarlo en un ambiente práctico y seguro, en la actualidad existen diversos servicios para contar con repositorios remotos bajo los sistemas de control de versiones de Git (GitLab, GitHub, BitBucket, entre otros), pero de alguna manera estamos limitados a ciertas características propios de cada servicio. Desde hace unos años apareció Gitea como una opción libre para contar con el servicio pero alojado de manera local en nuestra infraestructura, lo que me parece una interesante alternativa para quienes estamos acostumbrados a gestionar repositorios. A continuación voy a mostrar mi experiencia instalando Gitea a través de Docker, en la documentación de Gitea puedes revisar otras opciones.
Instalación usando Docker
Primeros Pasos
Lo primeo que hice fue generar una carpeta en donde voy a trabajar Gitea, en mi caso lo abrí con Visual Studio Code y generé una archivo YAML al que le denominé docker-compose.yml , el contenido de este archivo lo extraje de la documentación de Gitea, el cual correspondía a la instalación usando Docker y en donde se especifica el uso de Gitea en combinación con una base de datos MySQL.
version: "3"
networks:
gitea:
external: false
services:
server:
image: docker.io/gitea/gitea:1.23.1
container_name: gitea
environment:
- USER_UID=1000
- USER_GID=1000
+ - GITEA__database__DB_TYPE=mysql
+ - GITEA__database__HOST=db:3306
+ - GITEA__database__NAME=gitea
+ - GITEA__database__USER=gitea
+ - GITEA__database__PASSWD=gitea
restart: always
networks:
- gitea
volumes:
- ./gitea:/data
- /etc/timezone:/etc/timezone:ro
- /etc/localtime:/etc/localtime:ro
ports:
- "3000:3000"
- "222:22"
+ depends_on:
+ - db
+
+ db:
+ image: docker.io/library/mysql:8
+ restart: always
+ environment:
+ - MYSQL_ROOT_PASSWORD=gitea
+ - MYSQL_USER=gitea
+ - MYSQL_PASSWORD=gitea
+ - MYSQL_DATABASE=gitea
+ networks:
+ - gitea
+ volumes:
+ - ./mysql:/var/lib/mysqlLuego de contar con el archivo, dentro de VsCode abrí una terminal, en mi caso lo hice con GitBash para mayor facilidad, desde ahí ejecuté el siguiente comando:
docker-compose up -d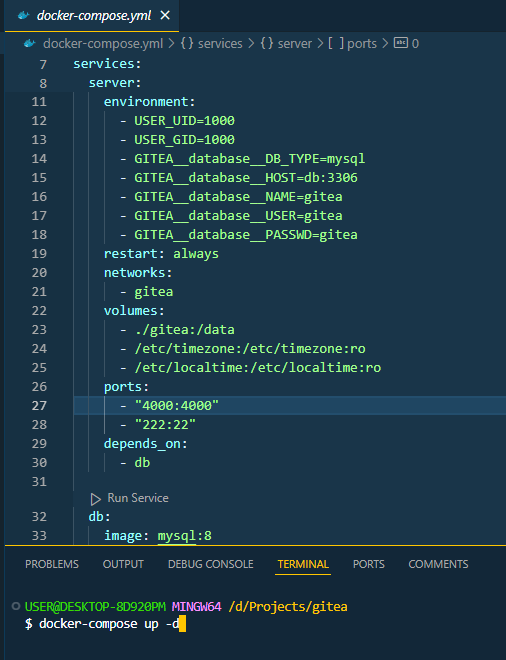
Ajustes requeridos
Un detalle que no debemos dejar de lado son los requerimientos para una instalación sin errores, uno de ellos es el contar con Docker Desktop corriendo en nuestro equipo. Por otro lado, si fueron curiosos y vieron la figura de arriba, en la línea 26 se define los puertos a emplearse, en mi caso el puerto por defecto «3000» lo tenía ocupado, por lo tanto, lo modifiqué a «4000», pero no basta hacer eso, aunque me tarde un poco en descubrirlo, es necesario también editarlo del archivo app.ini localizado dentro de la carpeta config.
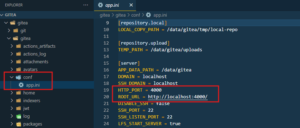
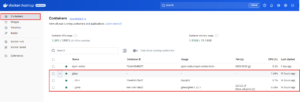
Para comprobar que todo funciona bien, lo podemos revisar en nuestro Docker Desktop.
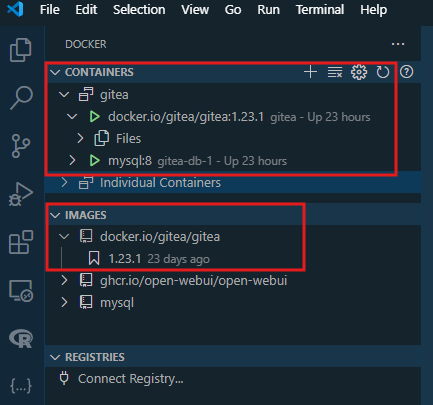
También, para quienes tienen el complemento de Docker en VsCode lo podemos apreciar al activarlo de la barra lateral.
Configuración de nuestro servicio
Ahora viene lo interesante, debemos ir a nuestro navegador web para abrir nuestro servicio local, en mi caso iré a: http://localhost:4000/. Cuando hagamos eso nos aparecerá una página para terminar de configurar el servicio con detalles que podemos editar, como por ejemplo el título de la página y lo más importante los datos como administradores. Nos referimos con introducir nuestro correo y una constraseña.
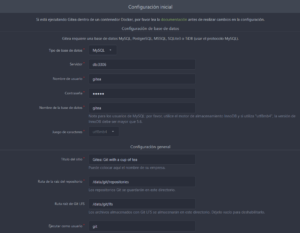
Pasos finales
Luego de introducir los datos requeridos en la configuración inicial podemos hacer click en el botón que dice «Instalar Gitea».
Dentro de nuestro Servicio Git
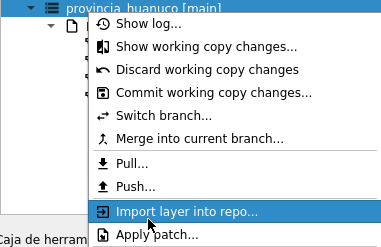
Una vez que pudimos levantar el servicio podemos iniciar creando un nuevo repositorio, aunque en mi caso lo que empecé hacer fue migrar repositorios que tenía en GitHub por ejemplo, para ello solo seleccionamos esa opción.
Luego seleccionamos desde el sitio, en este caso seleccionamos GitHub y luego podemos ir a nuestro repositorio que vamos a migrar para copiar la URL que usaríamos para clonarlo y lo insertamos en donde indica «Migrar / Clonar desde URL«.
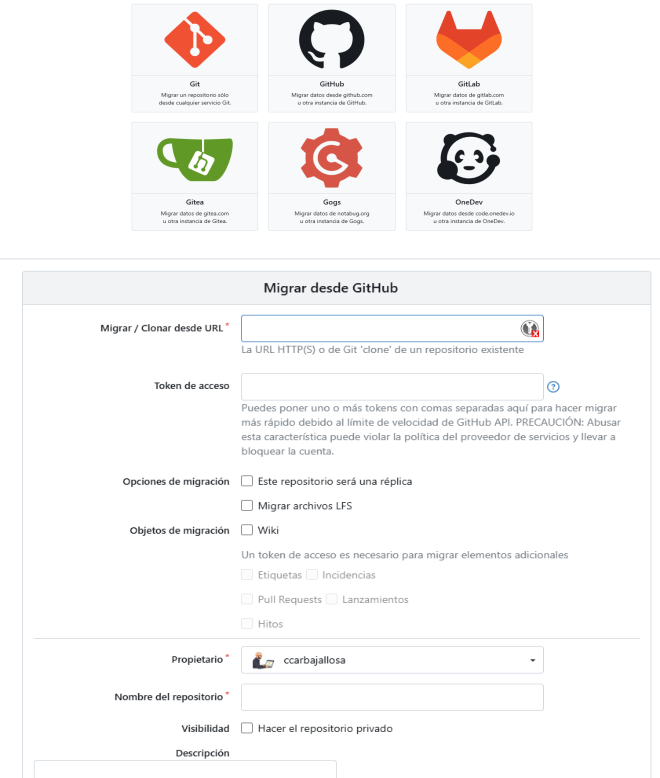
Opciones de Migración
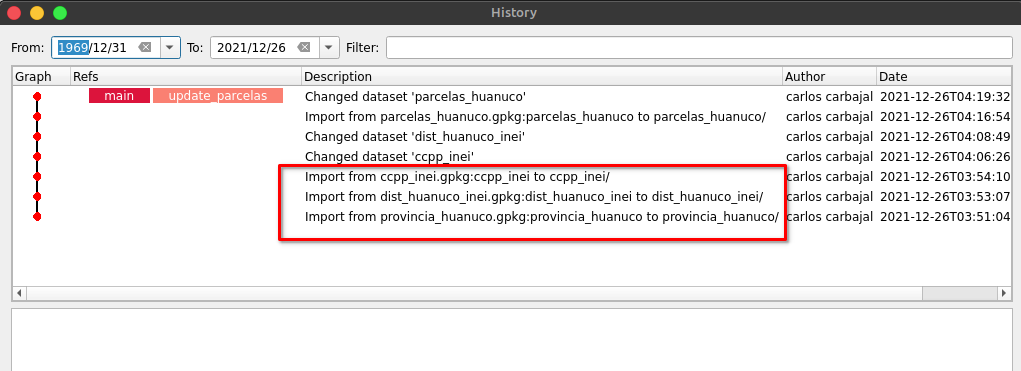
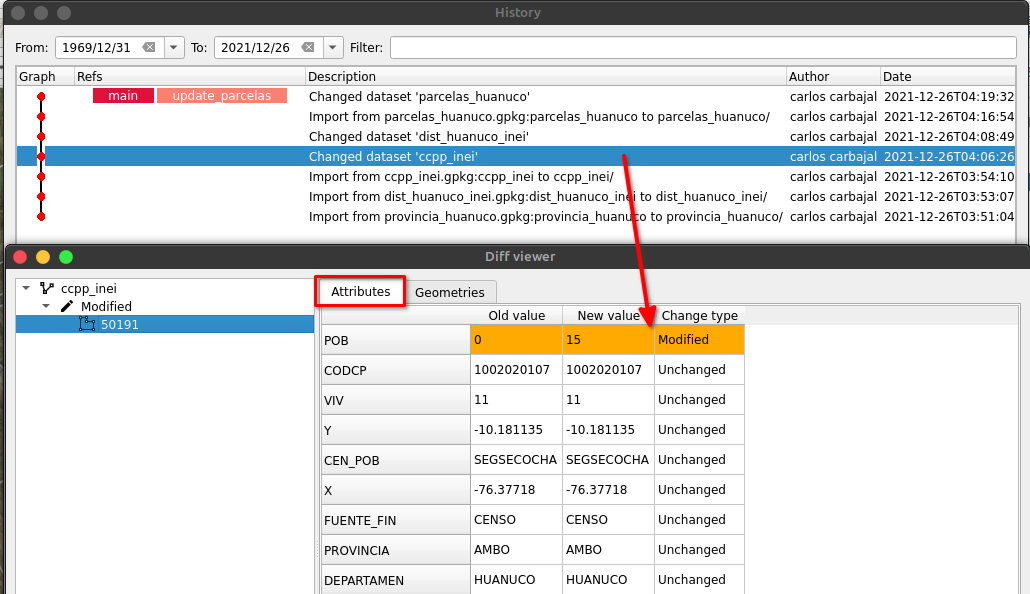
Un detalle que no quiero dejar de pasar en la posibilidad de que los repositorios que migremos pueden ser una réplica, esto quiere decir que estarían sincronizados con el sitio de origen en este caso de un repositorio de GitHub. Cuando listemos nuestros repositorios tendrán un ícono distinto a los otros.
Para mantenerlo actualizado con los últimos cambios que hagamos, no debemos olvidarnos de realizar esta sincronización.
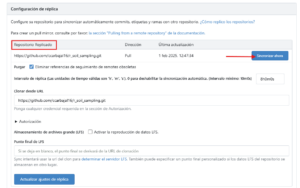
Nuevos Repositorios
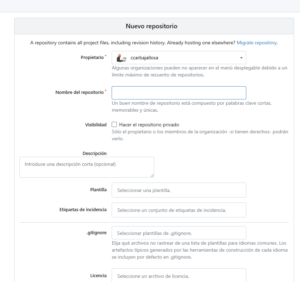
Bueno no dejemos de lado también la posibilidad de generar desde cero nuestros repositorios, muy similar a lo que ya conocemos.
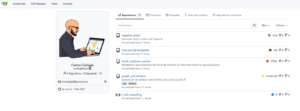
Luego que ya sea por migración o creando nuevos repositorios ya podemos visualizarlos si nos vamos a la pestaña de «Explorar» o también dentro de nuestro «Perfil».
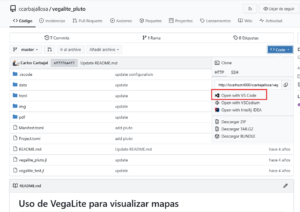
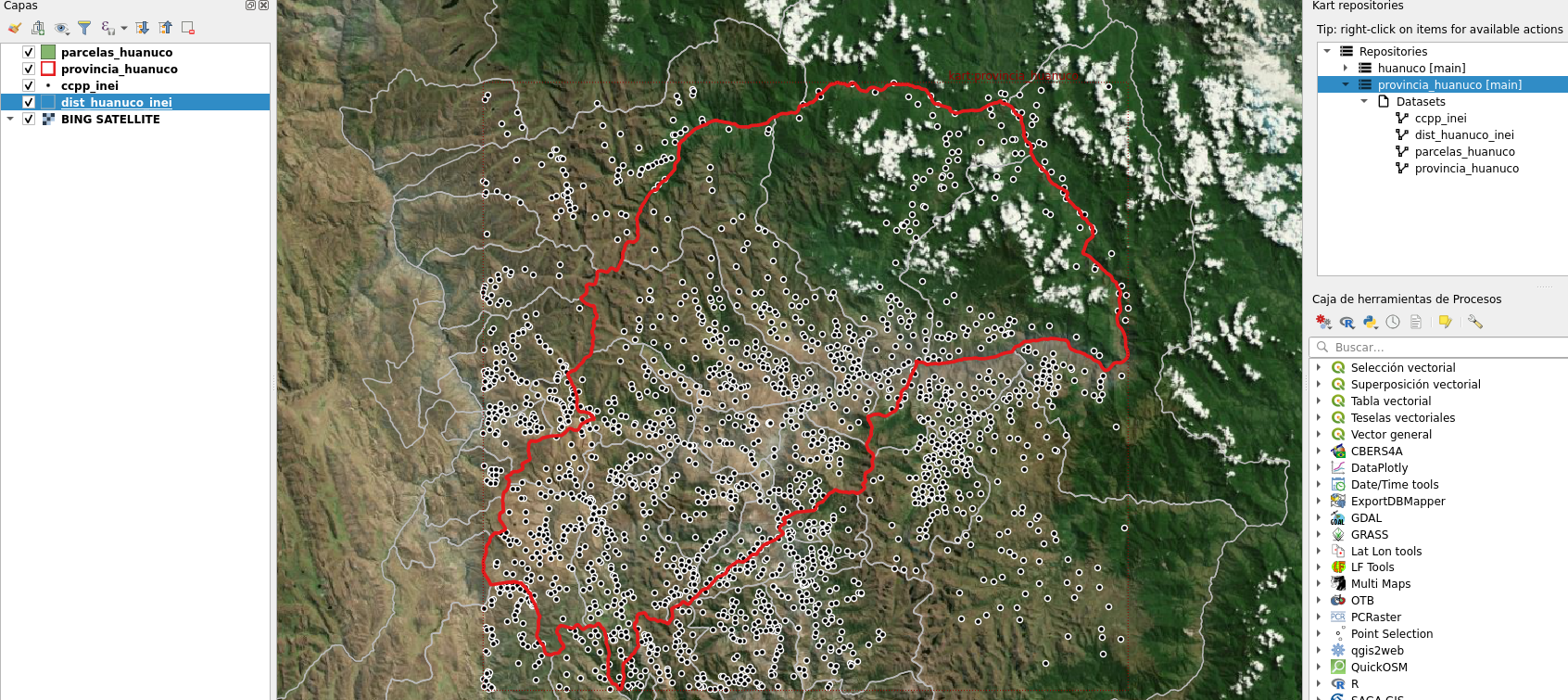
Trabajando con los repositorios
Ahora que tenemos nuestros repositorios podemos realizar los cambios o actualizaciones que sean necesarios, por lo tanto, debemos realizar el proceso de clonado, en este caso, nos dá varios opciones, pero creo que abrirlo dentro de VsCode considero que es lo más práctico, solo nos pedirá que seleccionamos una carpeta en donde se va a descargar.
Reflexión Final
Luego de esta experiencia de poder instalar un servicio autoalojado de Git para gestionar el desarrollo de mis proyectos, siento que tengo un mayor control de mi información, aunque es verdad que la ventaja de tener los servicios de GitHub en términos de colaboración y ser más visibles son muy valiosas, no pienso dejarlos, pero si algunos proyectos lo quisiera manejar de manera local con toda la posibilidad de aprovechar el sistema de control de versiones. Todavía no genero un repositorio desde cero, pero seguro será de un proyecto muy personal y cuando esté muy bien pulido lo podré compartir en los repositorios remotos.
Bueno, esto sería todo por ahora, en esta oportunidad no he generado un video porque todo fue muy rápido y considero que no es muy complicado si seguimos los pasos que se ha descrito, espero que sea de utilidad para quienes se animen. Hasta la próxima.





![\[f(x) = p * e^\frac {-x^2}{\beta}\]](https://www.educagis.com/wpcarlos/wp-content/ql-cache/quicklatex.com-e260906edc171653377227f3f62ea381_l3.png "Rendered by QuickLaTeX.com")