Introducción
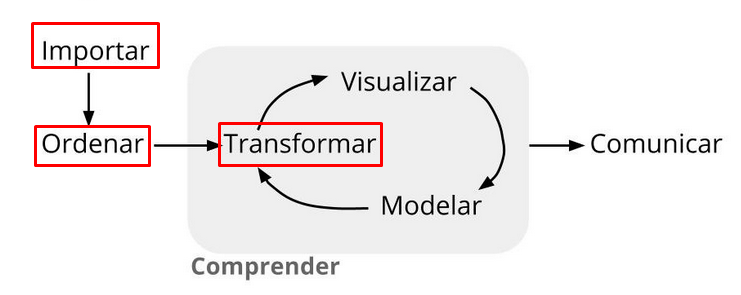
En esta oportunidad vamos a continuar presentando las opciones que tenemos empleando paquetes de Julia orientados a la ciencia de datos. Se tiene como principal objetivo lograr obtener resultados similares a los vistos en el post anterior, pero en esta oportunidad realizarlo en menos pasos aprovechando las ventajas de algunos paquetes que nos permiten desarrollar código digamos «encadenado» para una ejecución simultánea de operaciones, con la finalidad de preparar tablas de resultados según algunos criterios establecidos. Por otro lado, nos plantemos el reto de incluir la siguiente etapa del llamado «Proceso de análisis de datos«, es decir, la visualización a través de la generación de gráficos, los mismos que vamos a incluir como parte del código elaborado.
Encadenamiento de código en Julia
En Julia como ya lo venimos adelantando existe la opción de «encadenar» código empleando los llamados operadores Pipe (|>). Para lograr nuestro objetivo vamos a emplear otros paquetes de Julia, nos referimos a Queryverse, siendo uno de los más completos para ciencia de datos. De la misma manera exploraremos al paquete Chain.jl como otra alternativa en manipulación de datos encadenando código. En resumen vamos a demostrar las ventajas que tenemos al usar dos alternativas, primero la combinación DataFrames+DataFramesMeta y luego el uso del paquete Queryverse, que incluye varios paquetes para el manejo de datos tabulares, incluyendo la posibilidad de generar gráficos.
Uso de DataFramesMeta.jl
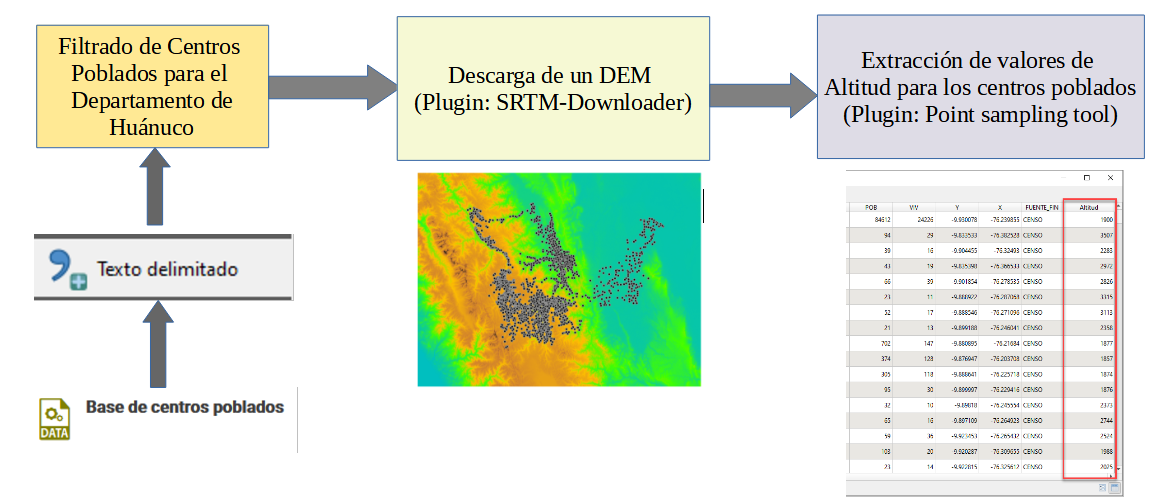
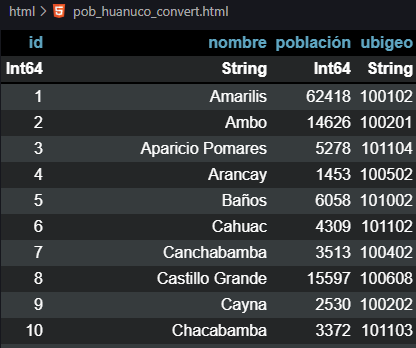
Si revisamos la documentación del paquete DataFramesMeta, apreciamos que @chain desde Chain.jl, forma parte de la lista de macros disponibles, es decir que podemos emplearlo para unir más de un macro a la vez. A continuación compartimos el código elaborado en Julia, con la diferencia que emplearemos otra fuente de datos, el mismo presenta mayores detalles como por ejemplo la altitud de los centros poblados.
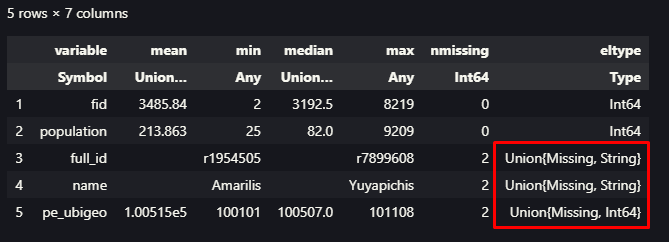
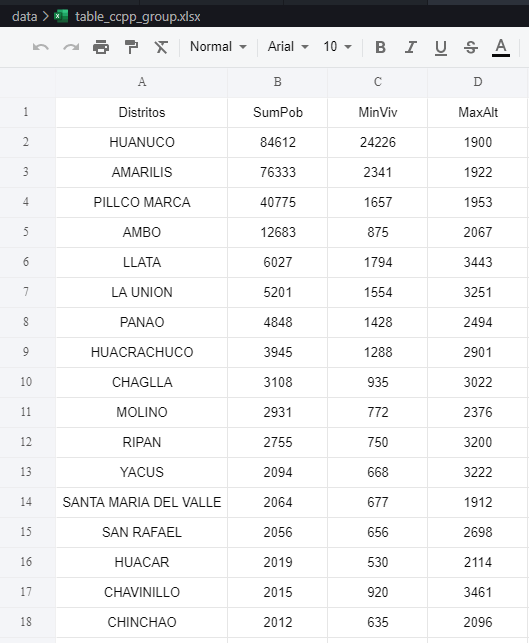
Si revisamos el código, vemos que iniciamos con el uso de los paquetes DataFrames y CSV para incorporar nuestros datos (table_ccpp_inei.csv), luego empleamos el macro @chain con la finalidad de ir encadenando macros como funciones. Un paso importante es el uso del macro @combine, que a diferencia de lo que vimos anteriormente, nos facilita crear y nombrar nuevas columnas definiendo simplemente funciones sobre nuestras columnas de origen. Para el caso del ordenamiento, se menciona la existencia del macro @orderby, pero al no funcionar sobre datos agrupados, empleamos el ya conocido sort. De la misma manera apreciamos el uso del macro @subset, que nos permite realizar filtros, seleccionando un subconjunto de filas sobre las columnas con valores numéricos. También empleamos el macro @transform para incorporar nuevas columnas de datos realizando algunas operaciones, teniendo la ventaja de poder asignar directamente los nombres a las nuevas columnas.
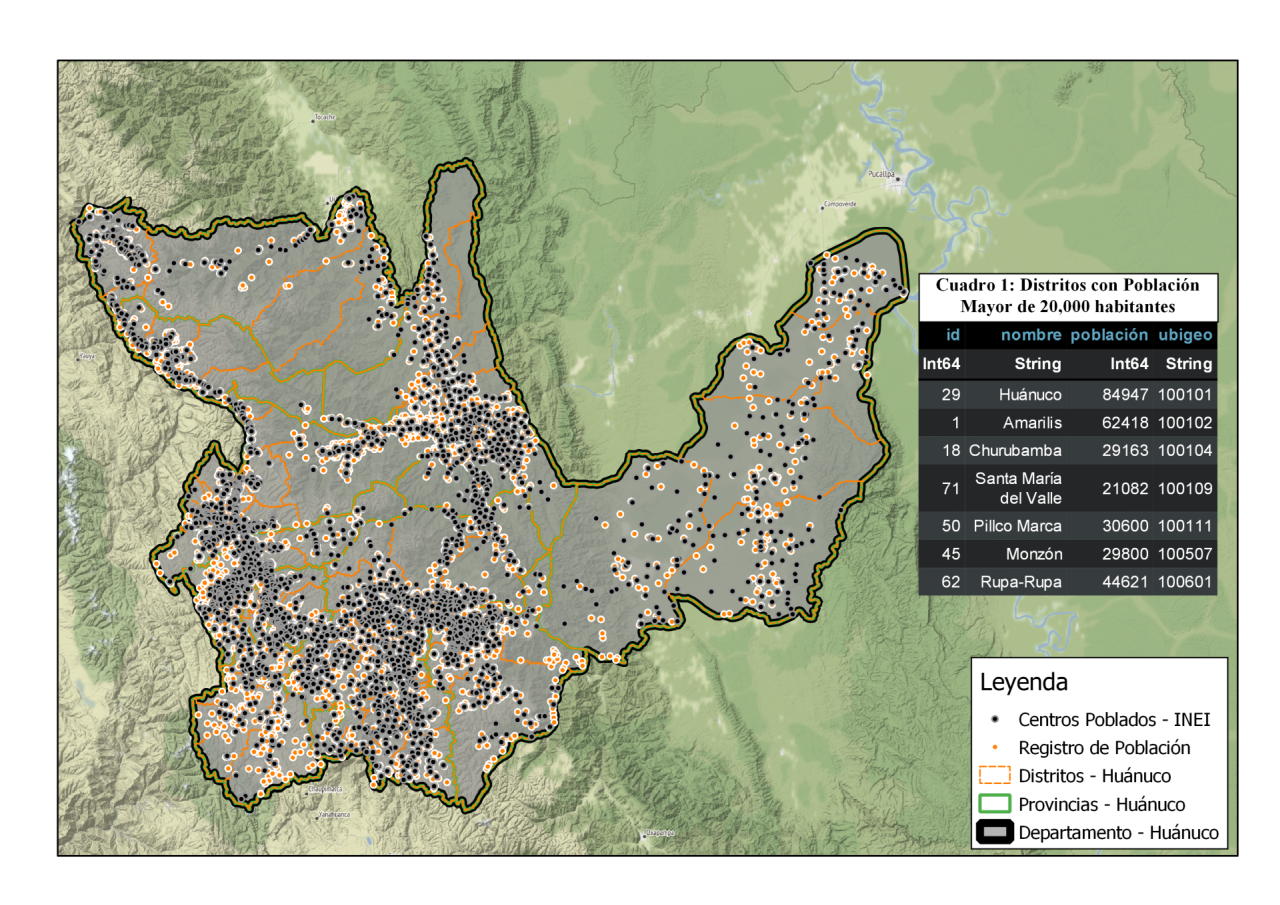
El resultado de este código se aprecia en la siguiente figura:
Uso del Queryverse.jl
Como lo menciona su documentación oficial, Queryverse.jl es un metapaquete que reúne varios paquetes para manejar datos en Julia, teniendo como su principal objetivo facilitar la instalación de todo el Queryverse de una vez. En el presente post exploraremos algunos de las ventajas de éstos paquetes, en especial para la manipulación de datos y la visualización. Para mostrar todo el ecosistema de Queryverse con los paquetes que lo integran se elaboró el siguiente diagrama.
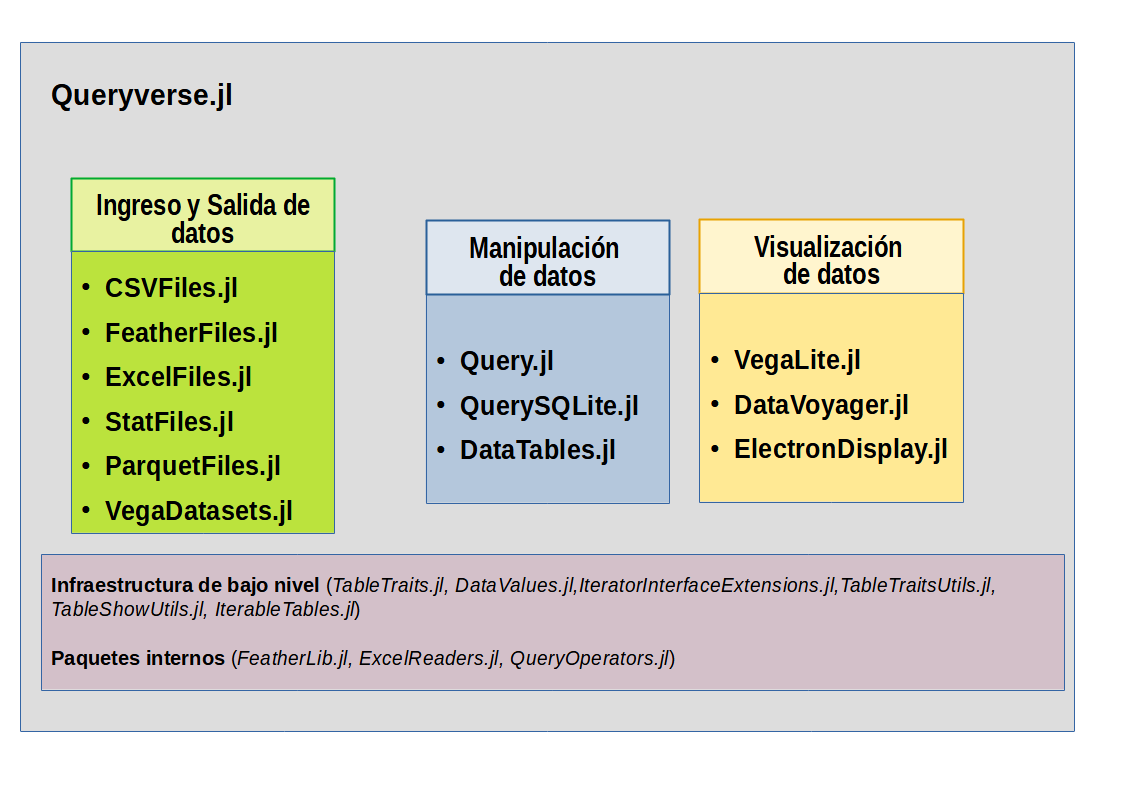
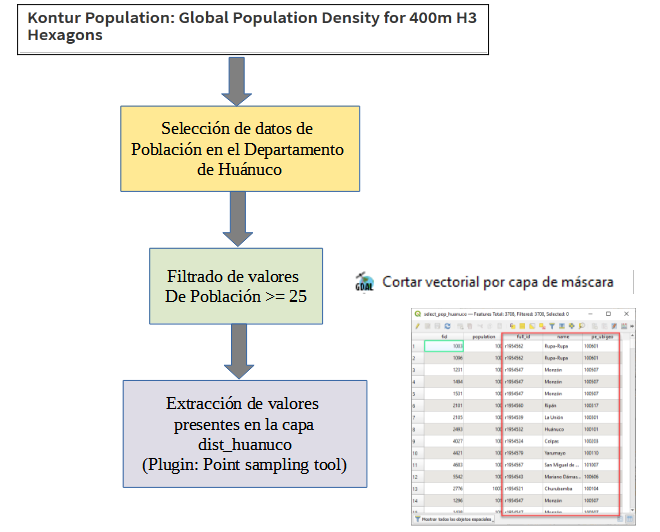
Vamos a compartir el código en donde empleamos Queryverse, el mismo asume que fue instalado, siguiendo los pasos ya vistos anteriormente.
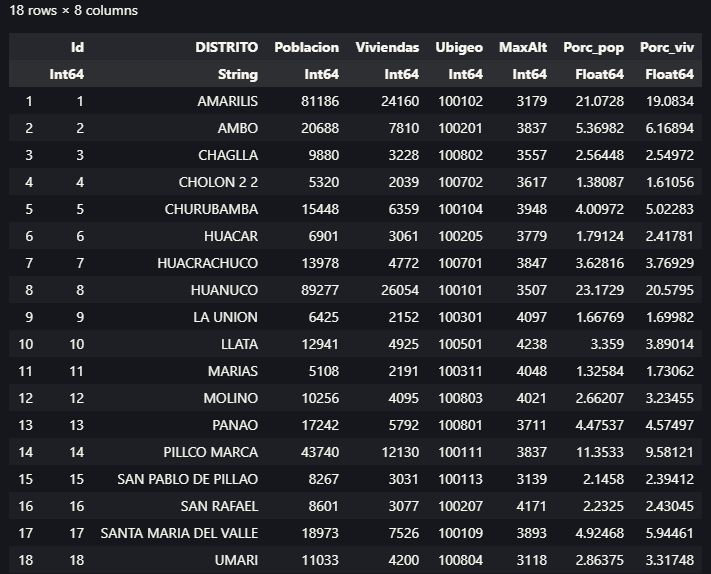
En este código hay muchas cosas por analizar, empezaremos con el hecho que solo hemos activado un solo paquete, pero como ya vimos integra varios otros que nos permiten trabajar. Como se aprecia el código se inicia con abrir nuestra tabla de datos, ahora simplemente usamos load(), esto gracias al paquete CSVFiles.jl, desde aquí empezamos a encadenar procesos, siendo uno de los primeros la realización de un filtro doble con @filter, que forma parte del paquete Query.jl, como la mayoría que estaremos usando. Algo nuevo que vemos sucede luego de hacer el agrupamiento con @groupby, porque debemos generar una named tuple, para establecer nuestras columnas de datos agrupados, emplearemos para eso el macro @map y dentro de { } definimos los valores.
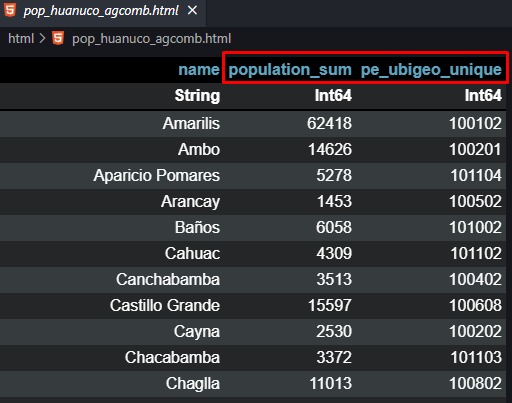
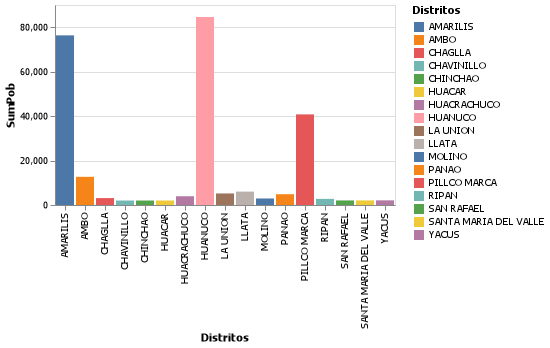
Para el caso del ordenamiento de datos, vamos a emplear @orderby_descending sobre el campo donde se almacena la suma de la población por distrito, logrando tener los valores mayores en las primeras filas. Ahora viene algo interesante, el uso del macro @tee, que en realidad si apreciamos el código fue empleado durante la generación de salidas, pero que nos permite que el código no se cierre y pueda realizar otras acciones, en nuestro caso, queríamos generar un gráfico, pero antes, guardar en formatos tanto de CSV como XLSX nuestro resultado.
En relación a la generación de gráficos, ahora simplemente generaremos un simple gráfico de barras a través de VegaLite.jl usando @vlplot, pero que en una próxima entrega será dedicado a mayor profundidad este como otros paquetes similares. Finalmente, tenemos la oportunidad también de salvar nuestro gráfico en formato PNG.
Reflexión Final
En esta oportunidad se pudo ver la gran flexibilidad que tenemos al emplear sobre todo Queryverse, aunque el uso de macros con DataFramesMeta nos permite realizar operaciones rápidas aprovechando sobre todo si trabajamos con DataFrames. Algo que no debo dejar de pasar, es el hecho que es muy recomendable no mezclar ambos procedimientos o conjunto de paquetes, sobre todo porque existen algunos macros que pueden originar conflictos por tener la misma denominación. En resumen, a pesar que solo es una introducción, hemos vistos varias cosas interesantes, aunque es verdad, podemos seguir explorando y profundizando mucho más, además está todavía pendiente el dedicarle toda una entrada al proceso de visualización de datos, por ahora solo se incluyo un simple gráfico de barras, pero Julia tiene todo un ecosistema muy variado para realizar todo lo que nos podemos imaginar.
Para quienes deseen reproducir todos los códigos, se actualizó el repositorio https://github.com/ccarbajal16/IntroDataScience. Muy pronto también se elaborará un video al respecto.