
Introducción
Una de las principales funciones de los Sistemas de Información Geográfica (SIG) es la posibilidad de realizar análisis espacial. En esta oportunidad, con el ánimo de introducirnos al campo del análisis de datos empleando capas de tipo vectorial, vamos a mostrar el uso del plugin de QGIS denominado Point selection algorithms. En resumen, vemos que es posible realizar diversos procesos de selección sobre una capa de puntos, empleando para ello un grupo de algoritmos que iremos explorando. Tal como lo mencionan en [3], dentro del contexto de la elaboración de mapas web, un desafío es la implementación de una regla que seleccione geometrías de puntos, por ejemplo, ciudades y picos con un atributo numérico claramente definido, por ejemplo, población y elevación, para ser empleados en dicha selección.
Detalles del Plugin
El plugin contiene herramientas para el cálculo de medidas para seleccionar puntos en el proceso de generalización cartográfica. Generalmente, ayuda a encontrar el máximo o mínimo local. Esta función también se puede utilizar con fines analíticos [1]. Cuando instalamos el plugin apreciamos en la caja de herramientas de procesos cuatro opciones, pero que en esencia digamos que son tres algoritmos que nos permite realizar distintos tipos de selección de puntos.
Discrete Isolation:
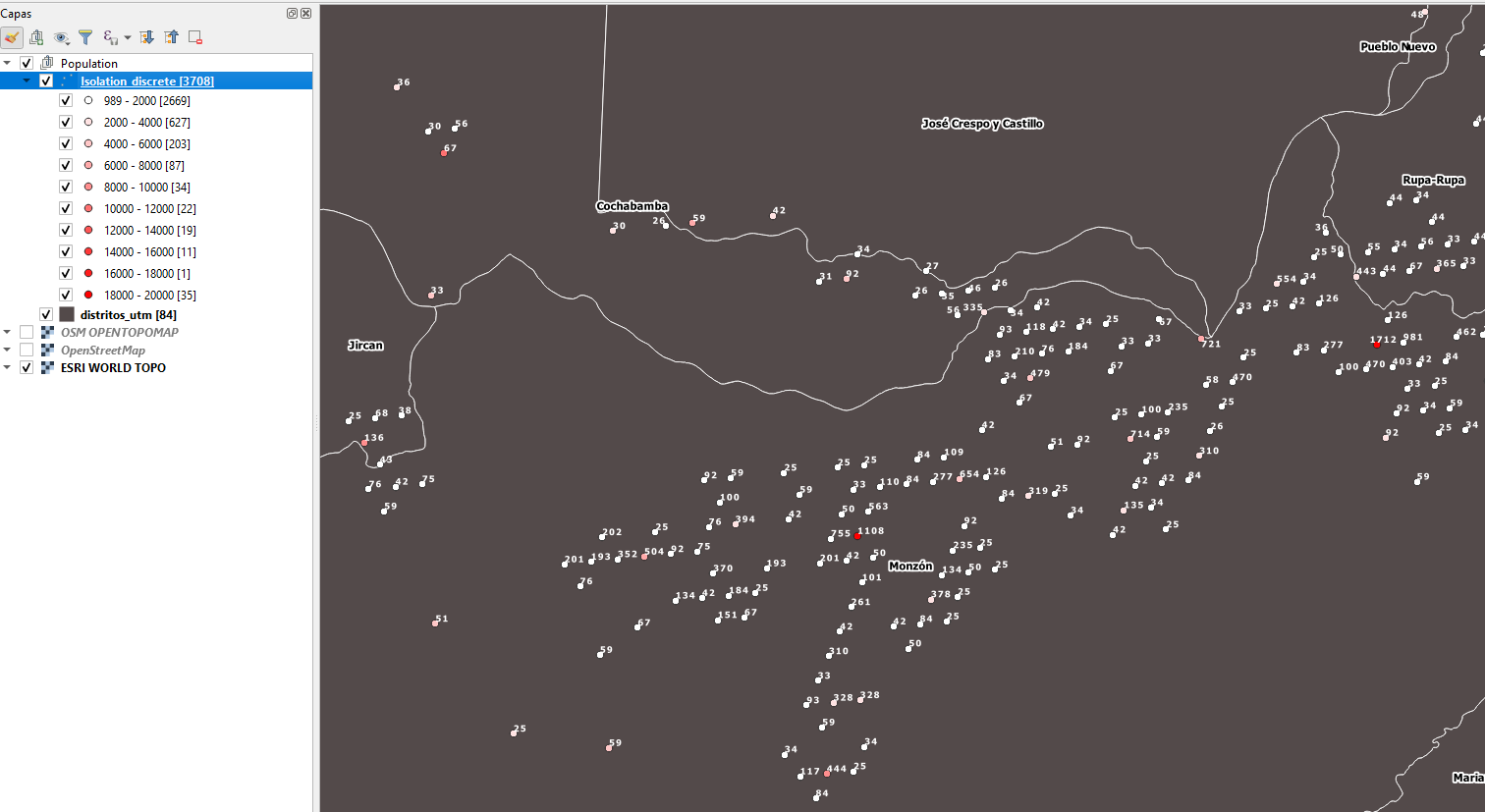
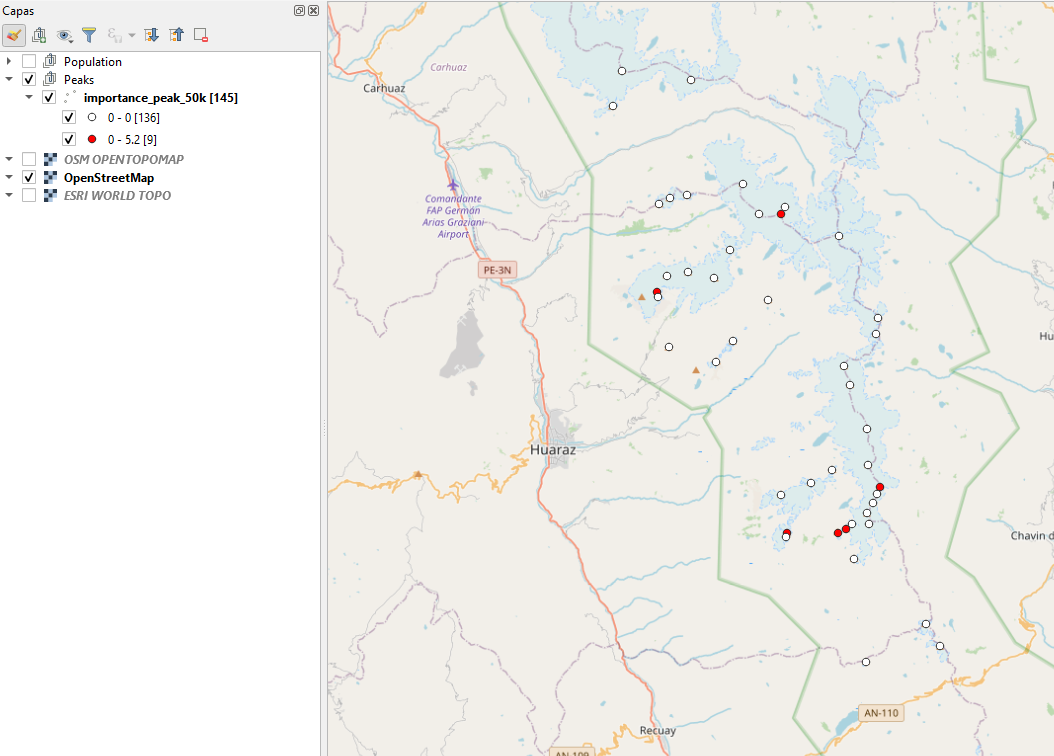
Calcula la distancia de aislamiento discreta (discrete isolation distance) para puntos con atributos numéricos. El concepto es similar al aislamiento topográfico (topographic isolation), el cual, para el caso de cumbres, corresponde a la distancia desde un pico hasta el punto más cercano con mayor elevación. Se puede tener una mejor comprensión si vemos la siguiente figura.

Fuente: Wikipedia
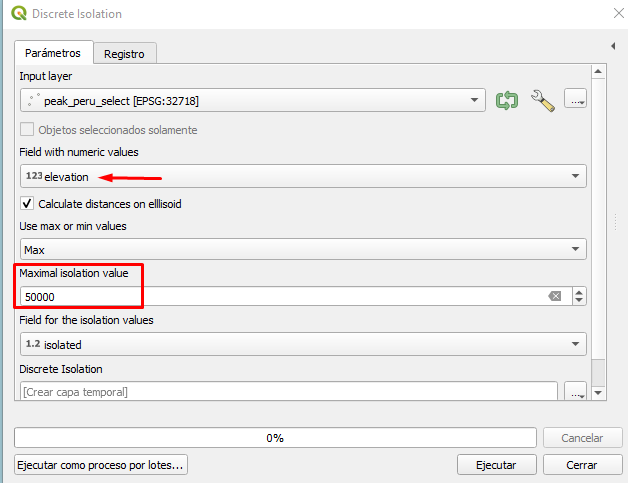
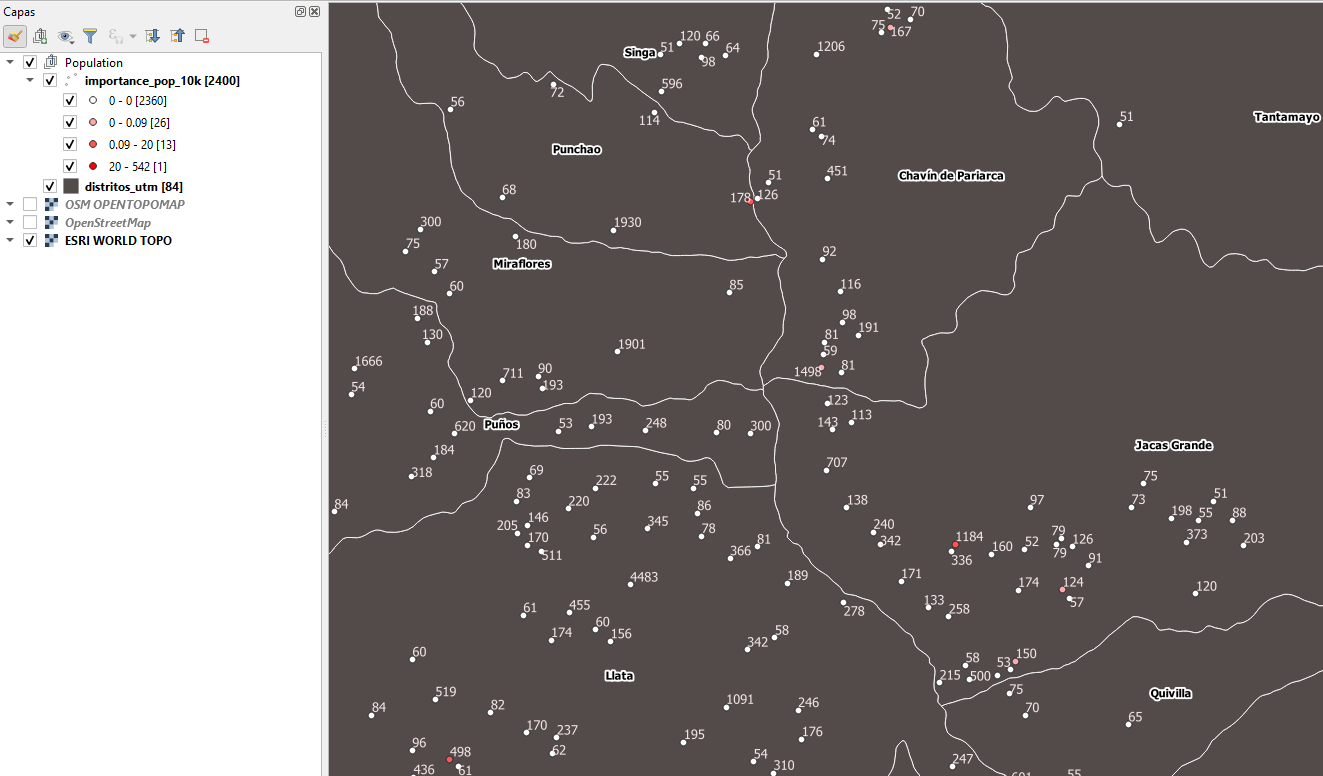
En general, cuando ejecutamos la opción en QGIS, debemos tener claro que el aislamiento es la distancia desde un punto al punto más cercano con un valor de atributo más alto (opción Máx.) O más bajo (opción Mínimo). Como valor de atributo se puede utilizar cada atributo numérico, por ejemplo, la elevación (para picos) o la población (para lugares poblados). La distancia de aislamiento se puede calcular en metros según el elipsoide por defecto o cartesiano en las unidades CRS. En la siguiente imagen por ejemplo, podemos ver que se ha seleccionado en base a datos de picos de montañas como puntos, los valores de elevación como atributo numérico y el valor de «máximo aislamiento» el valor de 50 km, es decir que nos calculará las distancias entre puntos que tengan este valor como el máximo encontrado.
Functional Importance:
Calcula la importancia funcional según Hormann, almacenando la mayor diferencia de valores de la función. Si revisamos la referencia [3] se puede apreciar la función mencionada.
![\[f(x) = p * e^\frac {-x^2}{\beta}\]](https://www.educagis.com/wpcarlos/wp-content/ql-cache/quicklatex.com-e260906edc171653377227f3f62ea381_l3.png "Rendered by QuickLaTeX.com")
x = distancia existente entre nuestra geometría de puntos
p = valor del atributo numérico (por ejemplo, la población)
β = variable para ajustar la rapidez para reducir el valor de la distancia y mantener la distancia entre los puntos cercanos.
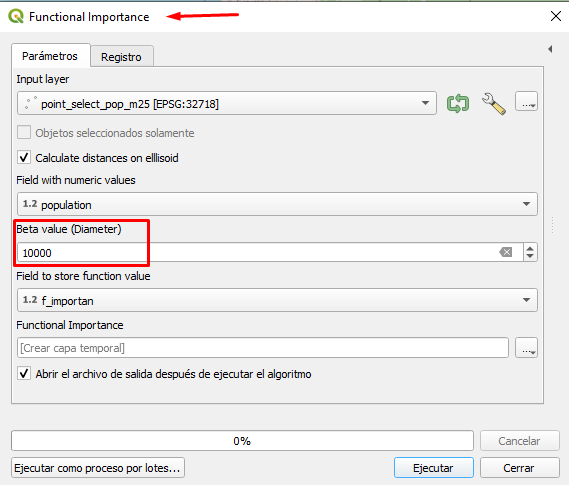
En la misma referencia, se muestra de manera visual el método de distancia funcional, empleando como ejemplo valores numéricos de población (parámetro p) y al realizar ajustes a la variable β, logra ajustar la carga de información y la distancia mínima entre puntos que se mostrarán en el mapa. La población da como resultado la selección o no del punto, siempre que exista la condición que la diferencia entre los valores de la función debe ser mayor que cero.
Para emplear el plugin, el campo con valores numéricos debe ser en caso de un lugar poblado el número de habitantes (population). El valor de Beta (β) es el diámetro del círculo alrededor del punto en metros; considerar que tiende el valor de la función hacia cero. Utilice este parámetro para asegurar una distancia mínima entre lugares, que debe seleccionarse.
Label Grid:
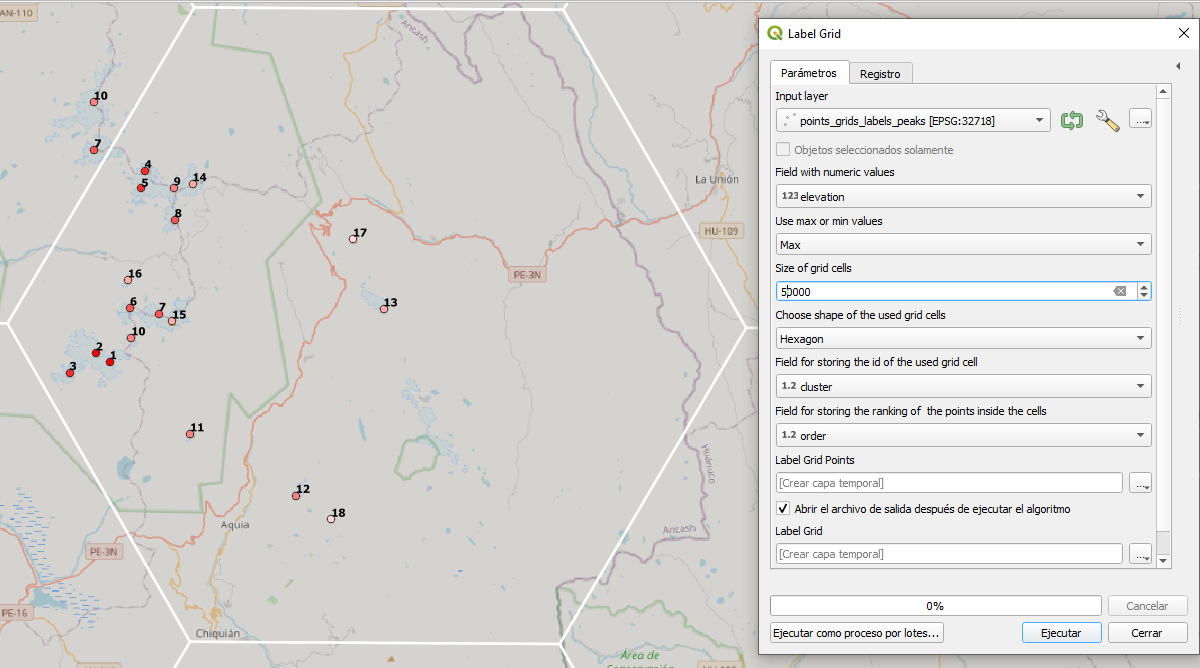
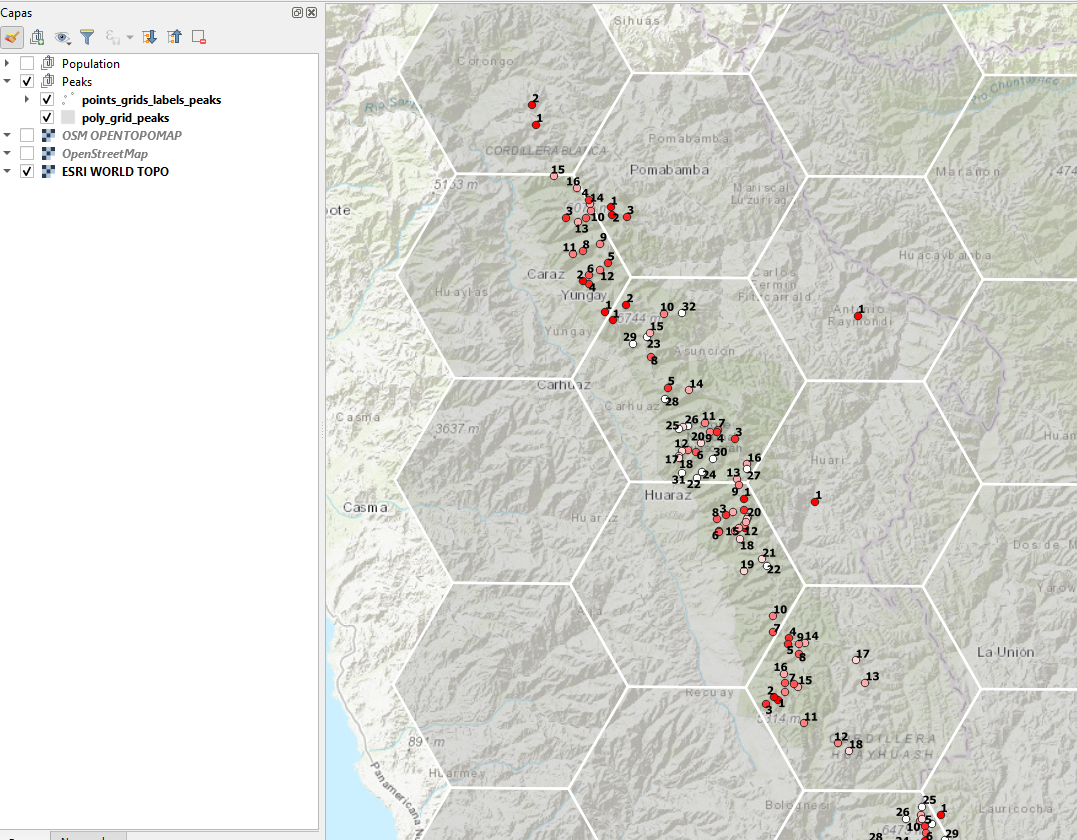
Crea una cuadrícula y comprueba cual de los puntos está contenida en alguna celda de la misma (un valor de -1 representa que el punto no se encuentra en la celda). Según la opción que elegimos, es decir, si optamos por el valor máximo, se establece un orden o ranking empezando con el número 1 correspondiente al valor más alto y se irá incrementando por cada punto que esté presente en la celda. En QGIS debemos considerar generar dos columnas para almacenar los resultados, en una se establece una clasificación realizada, con la finalidad de establecer un agrupamiento de valores, mientras que en la otra columna se incorpora el orden mencionado para cada celda. En la siguiente figura podemos apreciar la definición de los requisitos, entre ellos se seleccionó los valores máximos, el tamaño y forma de la celda. También debemos indicar las columnas para almacenar los resultados y finalmente indicar los nombres de los archivos, uno con una capa vectorial (polígono) que corresponde a la cuadrícula y el otro de puntos con los valores resultantes.
Point in Polygon:
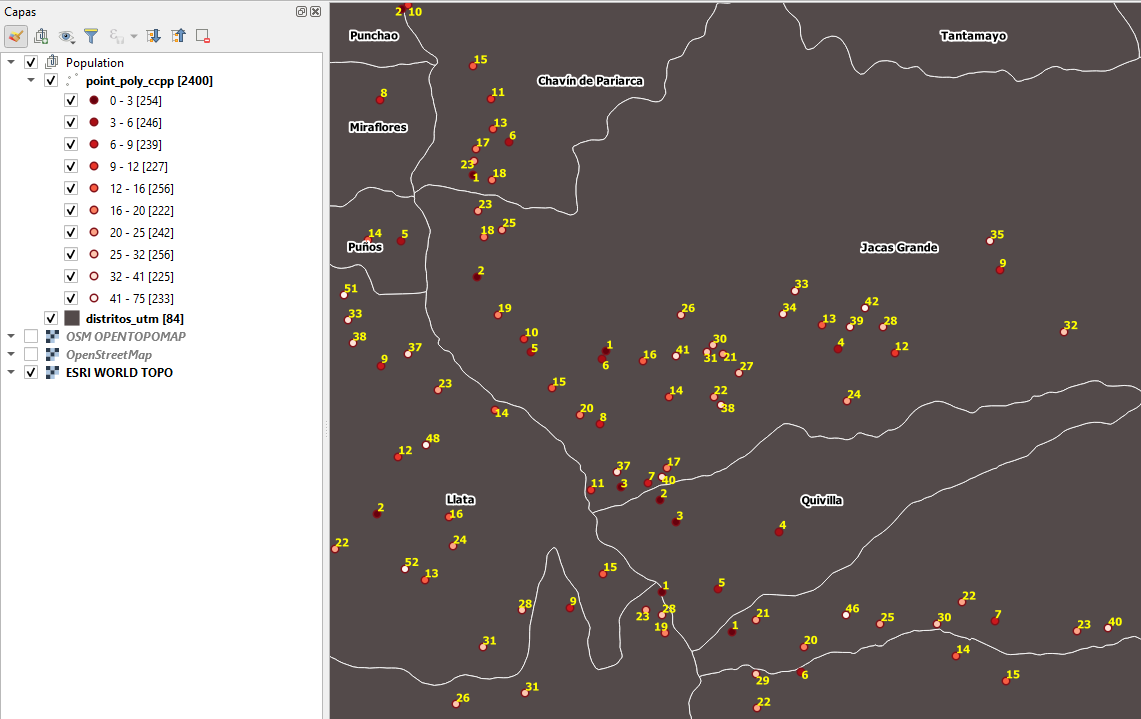
Tiene el mismo concepto del algoritmo previo, con la diferencia que ahora tenemos la oportunidad de emplear un polígono o una cuadrícula predefinida, siendo muy útil si queremos analizar por ejemplo ámbitos conocidos. En nuestro caso lo hicimos empleando polígonos que representan los limites de distrito de una Región en Perú, tal como se aprecia en la siguiente figura.
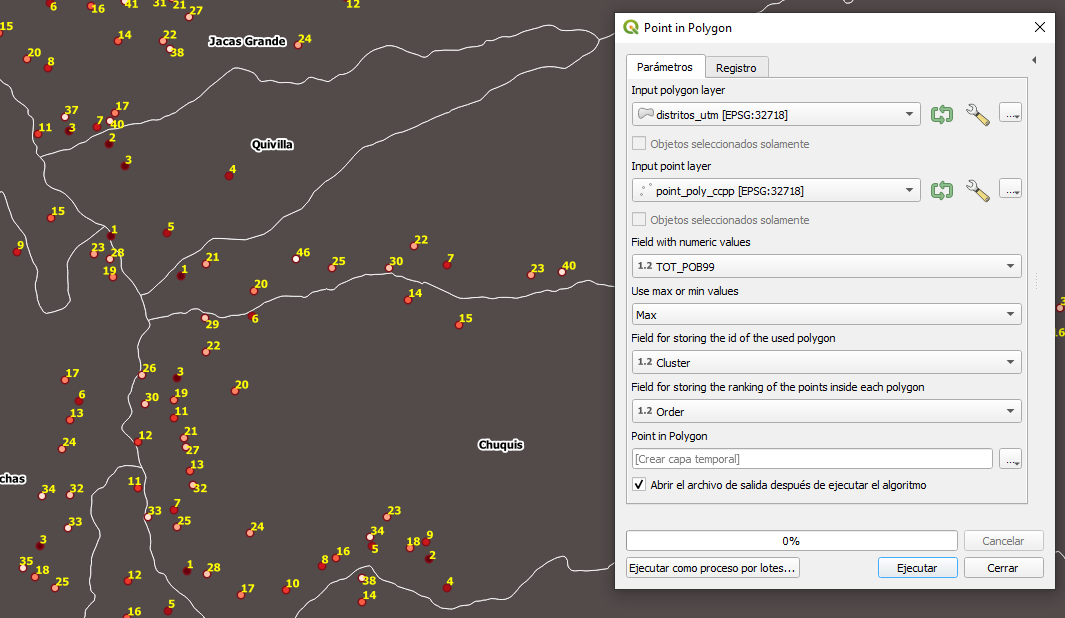
Metodología
Como escenario o ámbito que usamos para explorar el plugin se ha elegido zonas de Perú, para los datos de población nos enfocados sobre la Región de Huánuco, mientras que los datos extraídos de picos (peaks), están en su mayoría sobre la Región de Ancash, este último muy conocida por sus nevados.
Colección de Datos
Para esta demostración en relación a los datos de población se emplearon los que están disponibles en https://data.humdata.org/, al filtrar para este tipo de datos seleccionamos la mencionada en la referencia [5]. Estos datos a nivel mundial nos permite tener un geopackage con celdas de hexágonos que contienen valores de población. De toda esa información, se trabajó solo las que se encontraban solo la zona de trabajo, según se puede apreciar en la siguiente figura.
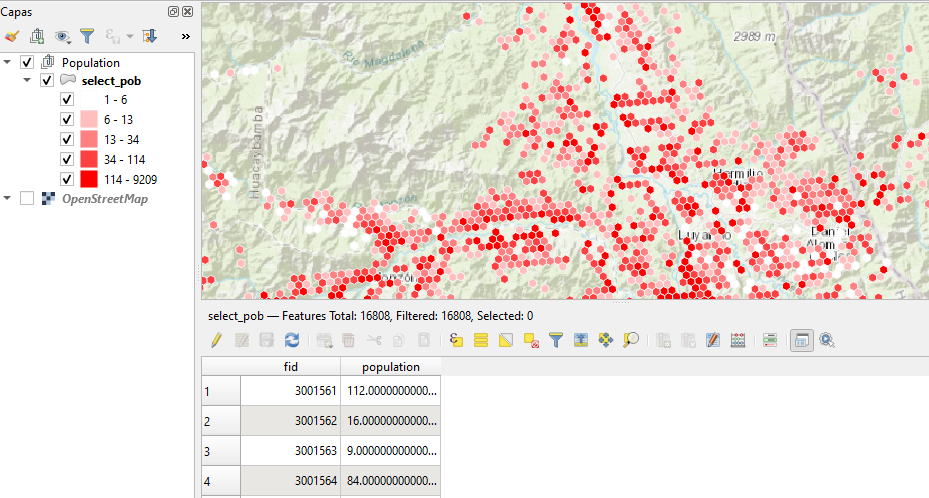
Como se estuvo mencionando, requerimos datos de puntos, por lo tanto, se hizo la transformación a puntos empleando herramientas como el Centroide o Punto en superficie. Ahora solo nos queda ajustar mejor nuestros datos a una superficie más definida, es decir, consideramos solo los puntos que estén dentro de la Región Huánuco. Al realizar las primeras pruebas, se comprobó que debido al volumen de datos los algoritmos demoraban en terminar de procesar, ante ello, se trabajó también con otros datos de población en función a centros poblados.
Para los datos de picos nos apoyamos con la extracción de datos del OpenStreetMap, pero desde QGIS se usó el plugin QuickOSM para contar con una capa en formato GeoJSON, luego se hizo un preprocesamiento para ajustar mejor el ámbito seleccionado y también algunos ajustes a la tabla de atributos.
En caso quieran probar el plugin, pueden descargar los datos empleados desde aquí.
Resultados Obtenidos
Como producto final de ejecutar los algoritmos descritos, mostramos a continuación una galería de imágenes, pero en resumen, se aprecia que el plugin nos permitió mostrar resultados esperados y un análisis profundo de todos ellos es necesario, también es importante mencionar que se emplearon una simbología de tipo graduado para mostrar mejor los resultados.
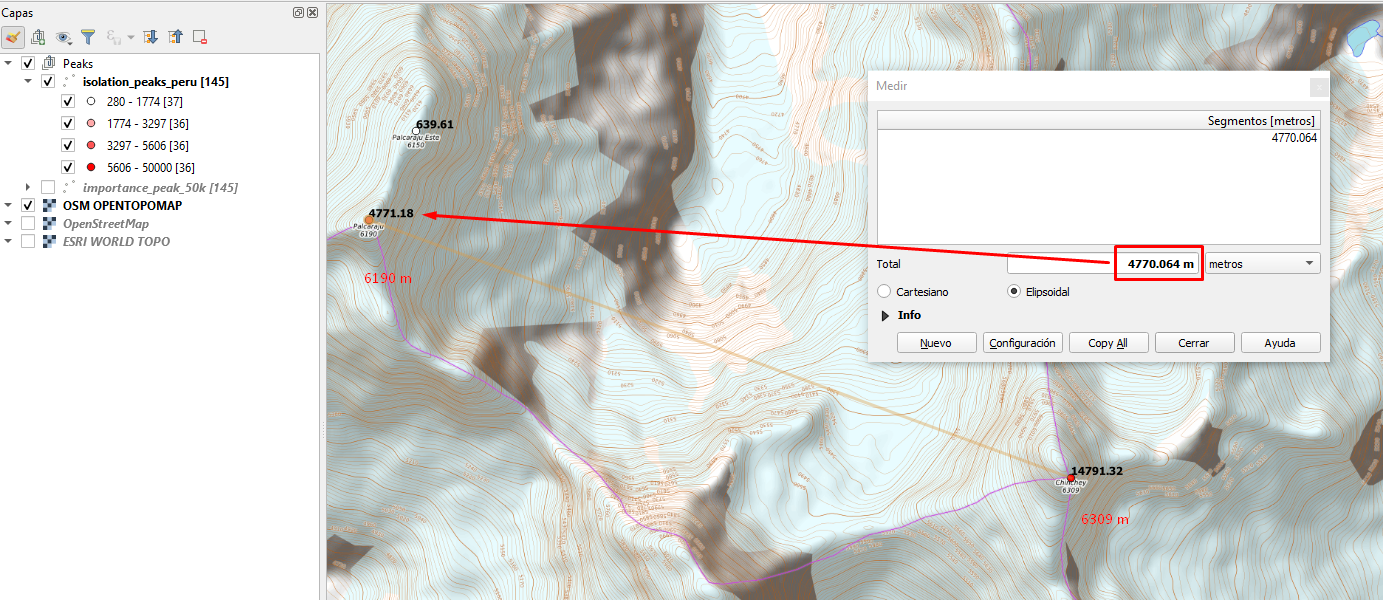
Reflexión Final
Por lo mostrado podemos darnos cuenta de que el plugin presenta más aplicaciones que lo visto hasta ahora, si nos ponemos a pensar en otros tipos de valores numéricos que podemos tener registrado como producto de nuestras actividades, esto sumado al hecho que no estamos limitados que deban ser por naturaleza puntos, ya vimos que podemos generarlos fácilmente, porque lo importante es evaluar una variable. En resumen, si logramos entender su uso nos abre un gran abanico de posibilidades para analizar datos y la relación existente con su espacio. Espero que puedan encontrar otras aplicaciones prácticas y lo comenten al respecto.
Se comparte un video en donde se pueda apreciar el procedimiento seguido para obtener los resultados presentados.
Referencias:
- Plugin QGIS: https://plugins.qgis.org/plugins/point_selection/
- Repositorio del Plugin: https://github.com/MathiasGroebe/point_selection
- Paper ICA: https://varioscale.bk.tudelft.nl/events/icagen2020/ICAgen2020/ICAgen2020_paper_12.pdf
- Wikipedia: https://es.wikipedia.org/wiki/Aislamiento_topogr%C3%A1fico
- Datos de población global:https://data.humdata.org/dataset/kontur-population-dataset